绪论
数据库系统概述
数据(Data): 描述事物的符号记录称为数据。 记录: 计算机中表示和存储数据的一种格式或一种方法。 数据库(DataBase,简称DB): 数据库是长期存储在计算机内、有组织的、可共享的大量数据的集合。 特点:
- 数据按一定的数据模型组织、描述和存储
- 可为各种用户共享
- 冗余度较小
- 数据独立性较高
- 易扩展
数据库管理系统(DataBase Management System,DBMS):位于用户与操作系统之间的一层数据管理软件,它为用户或应用程序提供访问DB的方法,包括DB的建立、查询、更新及各种数据控制。 主要功能如下:
- 数据定义功能
- 数据组织、存储和管理
- 数据操纵功能
- 数据库的事务管理和运行管理
- 数据库的建立和维护功能
- 其他功能
数据库系统(DataBase System, DBS):DBS是实现有组织地、动态地存储大量关联数据、方便多用户访问的计算机硬件、软件和数据资源组成的系统,即它是采用数据库技术的计算机系统。 组成: 计算机硬件、数据库、数据库管理系统、应用软件、数据库管理员
数据库技术:是研究数据库的结构、存储、设计、管理和使用的一门软件学科。
数据模型
模型: 现实世界特征的模拟和抽象 数据模型定义:能表示实体类型及实体间联系的模型 要求:
- 能比较真实的模拟现实世界
- 容易为人所理解
- 便于在计算机上实现
概念数据模型
按用户观点对数据建模,是对现实世界的第一层抽象,如ER图。主要用于数据库设计,是数据模型建立的基础。
实体:客观存在并可相互区别的事物。 属性:实体所具有的某一特性称为属性。用属性来刻画实体。 码:唯一标识实体的属性集,如学号。 域:属性的取值范围称为该属性的域。 实体型:具有相同性质的实体必然具有共同的特征和性质。 实体集:同型实体的集合。 联系:可分为一对一,一对多,多对多。
逻辑数据模型
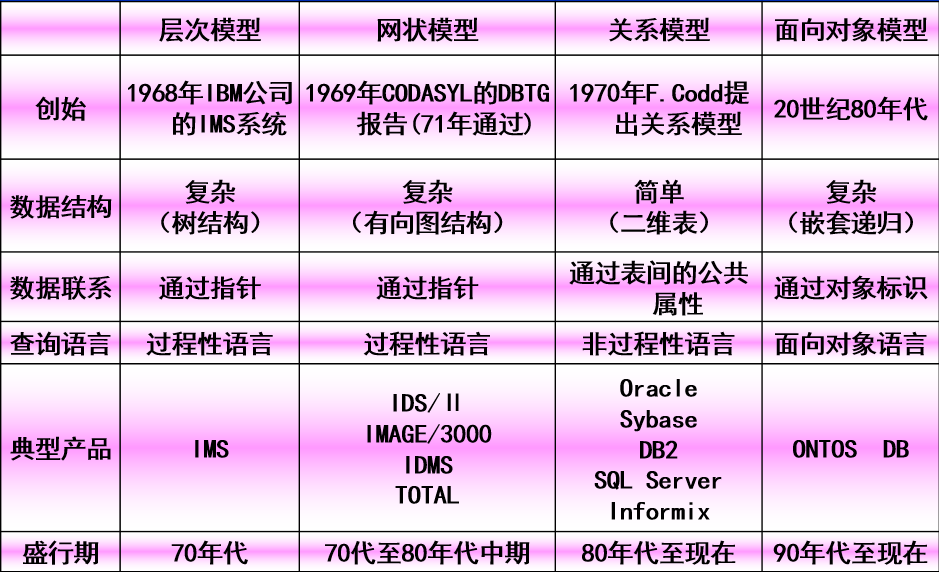
直接面向数据库的逻辑结构,是对现实世界的第二层抽象。可分为:网状、层次、关系、面对对象等;也可分为模糊、时态、空间、时空、概率、粗糙、分形等。组成包括:数据结构、数据操作、数据的约束条件。
层次数据模型: 层次数据模型对应数据结构中的树形结构:
- 有且只有一个称为根的结点
- 当结点数大于1时,除根节点外的结点可以分为M个互相不相交的有限集,其中每一个集合又是一棵数。
数据操纵:查询、插入、删除和修改 数据约束条件:
- 进行插入操作时,如果没有相应的双亲结点值,不能插入子女结点值。
- 进行删除操作时,如果删除双亲结点值,则相应的子女结点值也被删除。
- 进行修改操作时,应修改所有相应记录,以保证数据的一致性。
网状数据模型: 针对数据结构中的图
面向对象的数据模型: 最关键的两个概念: 对象:现实世界中实体的模型化 类:对象类型和对这个对象模型进行的操作方法
数据库系统结构
数据库系统的三级模式结构
- 外模式/模式映像
- 内模式/模式映像
数据库系统的组成
硬件平台及数据库
软件
人员
- 数据库管理员
- 系统分析员和数据库设计人员
- 应用程序员
- 用户
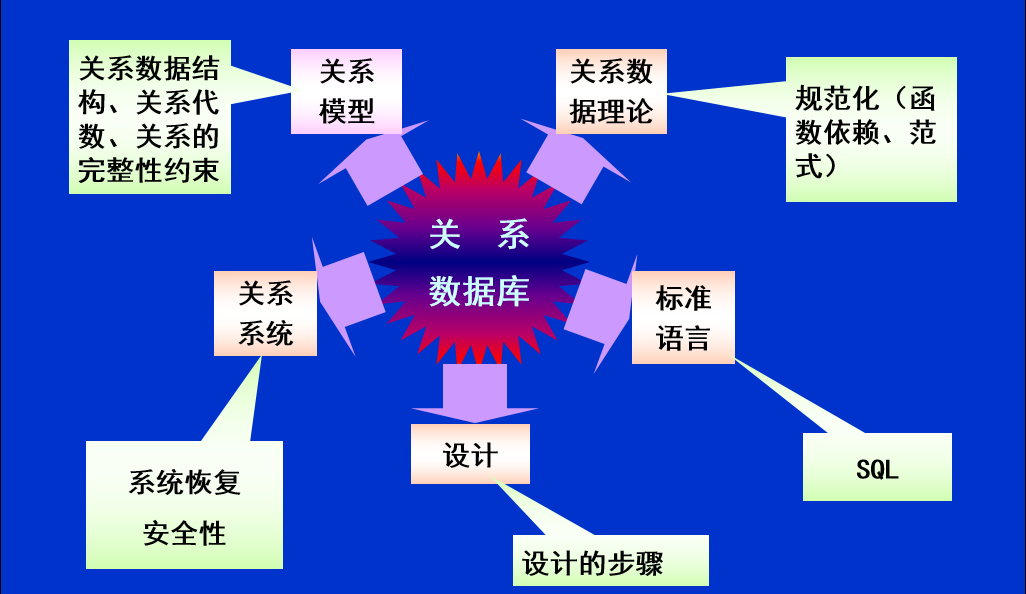
关系型数据库理论
关系模型概述
关系数据结构
域:是一组具有相同数据类型的值的集合
域的笛卡儿积:给定一组域D1,D2,...,Dn,其笛卡尔积为:
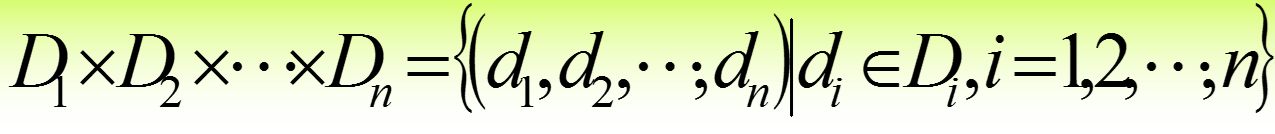
关系
关系:D1×D2×…×Dn的子集叫做在域D1,D2,…,Dn上的关系,记做:R(D1,D2,…,Dn)。
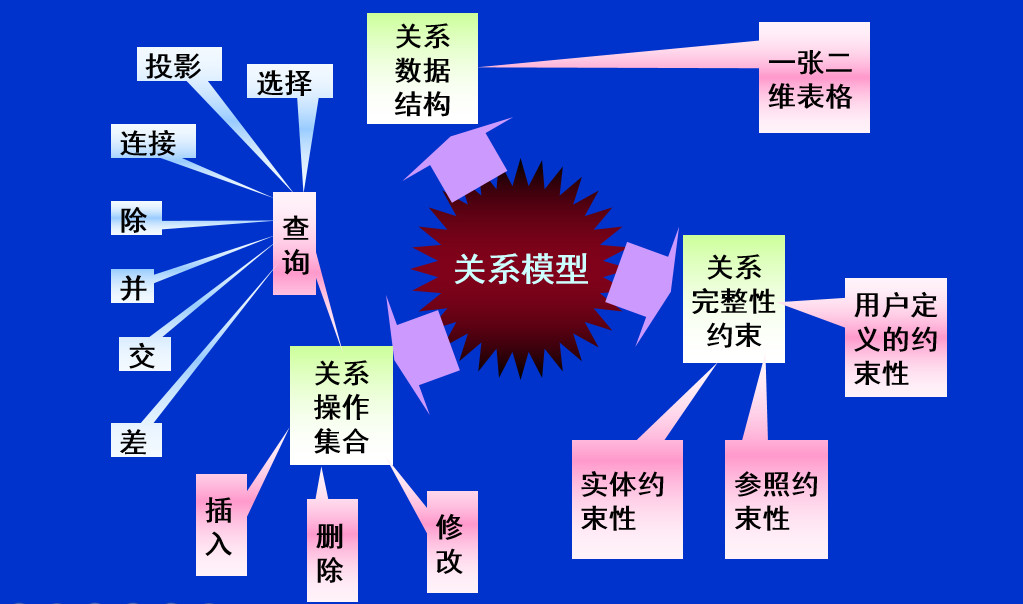
关系是笛卡尔积的有一定意义、有限的子集。 关系也是一个二维表,表的每一行对应一个元组,表的每一列对应一个域。 对每列起一个唯一的名字,称为属性。 n元关系有n个属性。 当n=1时,称该关系为单元关系; 当n=2时,称该关系为二元关系。 若关系中的某一属性组的值能够唯一地标识一个元组,则称该属性组为候选码。 若一个关系有多个候选码,则选定其中一个作为主码。 候选码的诸属性称为主属性。不包含在任何候选码中的属性称为非主属性或非码属性。
关系的性质:
- 同质的列
- 不同属性应该有不同的名称
- 属性是无序的
- 元组不能重复
- 元组无序
- 分量是原子(即每一个分量都必须是不可分的数据项)
关系模式
在数据库中要区分型和值,型是指关系模式,值是指关系。
关系: 一张二维表格,其中每一行为一元组,每一列为一属性。
关系模式: 关系的描述称为关系模式。它可以形式化的表示为: R(U, D, dom, F) 其中: R:关系名 U:组成该关系的属性集合 D:属性来自的域 dom:属性向域的映象集合 F:属性间数据依赖关系集合
关系模式与关系的关系:
- 关系模式是静态的,稳定的
- 关系是动态地,随时间不断变化的
- 关系是关系模式在某一时刻的状态和内容
关系的完整性
关系模型的完整性规则是对关系的某种约束条件。
关系的三类完整性约束
- 实体完整性
- 参照完整性
- 用户定义的完整性
实体完整性
若属性A是基本关系R的主属性,则属性A不能取空值。
参照完整性
外码 设F市基本关系R的一个或一组属性,但不是关系R的码。Ks是基本关系S的主码。如果F与Ks相对应,则称D是R的外码。 并称基本关系R为参照关系,基本关系S为被参照关系或目标关系。 关系R和S不一定是不同的关系。
若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:
- 或者取空值(F的每个属性值均为空值)
- 或者等于S中某个元组的主码值
用户定义的完整性
针对某一具体关系数据库的约束条件
关系代数
关系代数是一种抽象的查询语言,它用作对关系的运算来表达查询。
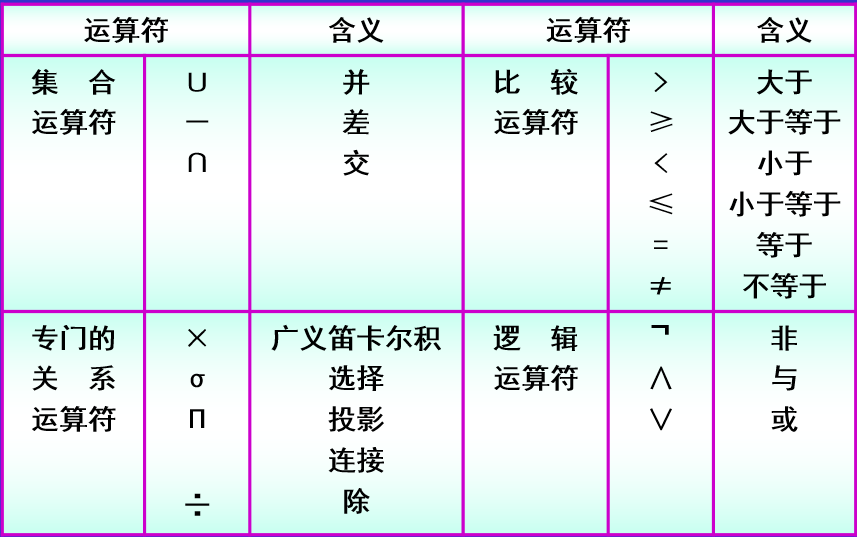
传统的集合运算
- 并
- 差
- 交
- 笛卡儿积
专门的关系演算
选择 从关系R中选取使得逻辑表达式F为真的元组,这是从行的角度进行的运算。 投影 从关系R中选取若干属性列组成新的关系,这是从列的角度进行的运算。 需要消除重复行,因此有可能导致某些元组被取消。 连接 从两个关系的笛卡尔积中选取属性间满足一定条件的元组
- 等值连接:要求选取的A,B属性组的值相等
- 自然连接:特殊的等值连接,要求把重复属性列去掉
如果把舍弃的元组也保存在结果关系中,而在其他的属性上填空值(NULL),那么这种连接叫做外连接。 如果只保留左边关系中要舍弃的部分,叫做左外连接; 如果只保留右边关系中要舍弃的部分,叫做右外连接。
除
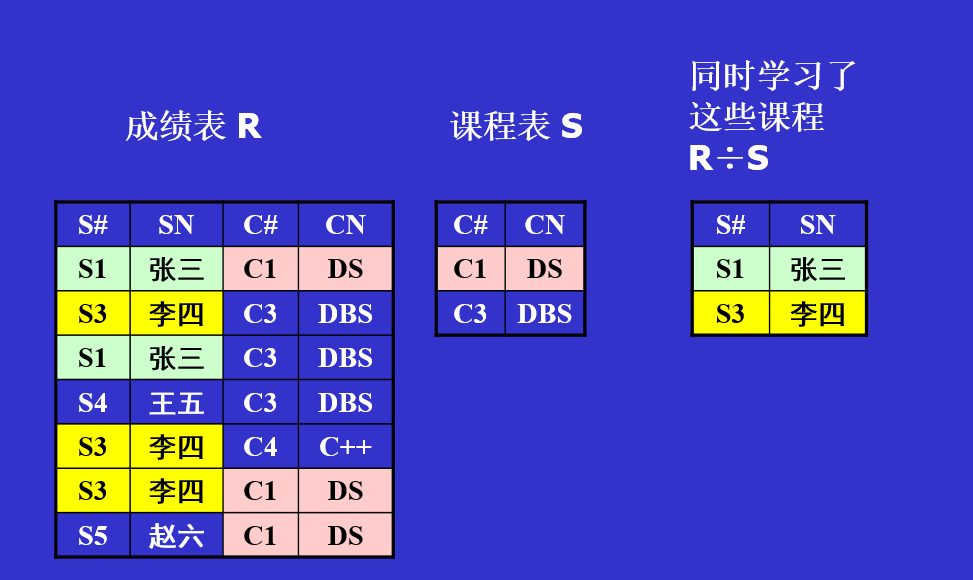
SQL数据语言
SQL概述
产生与发展
- 1974年由Boyce和Chamberlin提出
- 1975-1979年,IBM的System R上实现
- 1986年,ANSI通过SQL标准
- 后来相继提出SQL-89与SQL-92标准
- 目前,大多数数据库均采用SQL作为共同的数据存取和标准接口
SQL的特点
- 综合统一
- 高度非过程化
- 面向集合的操作方式
- 一种语法结构两种方式
- 语言简洁,易学易用
SQL基本概念
SQL支持关系数据库三级模式结构,其中:
- 外模式——视图和部分基本表(不能独立存在)
- 模式——基本表(独立存在,关系-基本表-存储文件一一对应)
- 内模式——存储文件(存储文件的逻辑结构组成了关系数据库的内模式)
SQL对象
SQL对象包括数据库、表、视图、属性名等,这些对象名符合一定规则:
SQL SERVER 1-30字符 ACCESS 64字符 ORACLE 限制为8个字符
应以字母开头,其他字符可以使字母、数字、下划线
SQL语句
- 尖括号"<>"中的内容为实际意义
- 中括号"[]"中的内容为任选项
- [,...]意思是等等
- 大括号"{}"与竖线"|"标明此处为选择项,在所列举的各项中仅需选择一项。
- SQL中的数据项(包括列项、表和视图)分隔符为",";其字符串常数的定界符用单引号"'"表示。
数据定义

数据库的创建与删除
创建数据库
CREATE DATABASE <数据库名>;
CREATE DATABASE Mydb;
删除数据库
DROP DATABASE <数据库名> [,<数据库名>] [,...];
DROP DATABASE Mydb;
表的创建与删除
创建基本表
CREATE TABLE <表名>
(<列名> <数据类型> [<列级完整性约束条件>] [<列名> <数据类型> [ <列级完整性约束条件> ] [,...] ] [,<表级完整性约束条件>] [,..]);
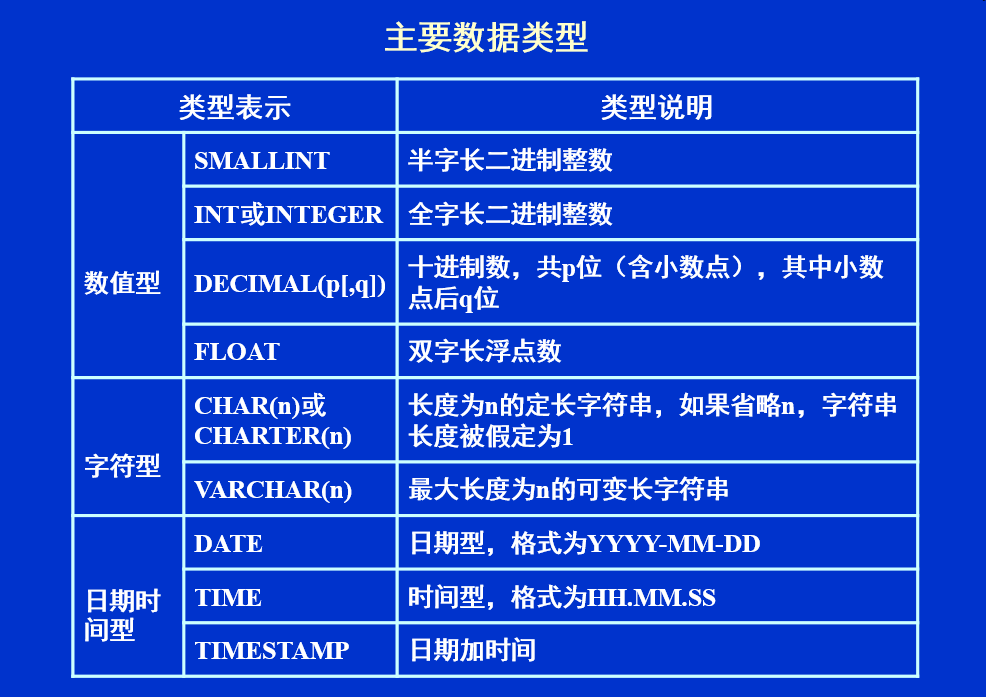
约束条件:
- 列级完整性约束条件——只能用于列
- 表级完整性约束条件——只能够用于一张中的多列
SQL完整性约束条件
- NOT NULL或NULL,列级,是否允许为空
- UNIQUE,列级,唯一性约束
- DEFAULT,列级,默认值约束
- CHECK,列级,检验约束,为插入列中的数据指定约束条件
- PRIMARY KEY,表级,主键约束,使得主键的数值在每一行中各不相同,不能为空
- FOREIGN KEY,表级,外键约束,是参照完整性约束
举例
创建学生表:Student(sno, sname, sdate, ssex, sdept)
Create Table Student(
sno char(5) not null unique,
sdate date,
ssex char(2) default '男',
sdept char(2)
Constraint C1 Check (ssex In ('男', '女')));
删除基本表
DROP TABLE <表名>;
举例
DROP TABLE Student;
表结构的修改
ALTER TABLE <表名>
[ADD ( <新列名> <数据类型> [<完整性约束条件>][,...])]
[DROP <完整性约束名>]
[MODIFY ( <列名> <数据类型> [,...])];
举例
在Student表中增加‘籍贯native_place’列,数据类型为字符型
Alter Table Student
Add native_place Varchar(50);
删除Student表中学生姓名必须取唯一值的约束条件
Alter Table Student
Drop unique(sname);
修改Student表中sname列的数据类型为定长字符型
Alter Table Student
Modify sname char(8) unique;
建立和删除索引
建立索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名> (<列名> [<次序>] [, <列名> [<次序>] ] [,…]);
举例
Create unique Index stusno_ind
On Student (sno ASC);
删除索引
DROP INDEX <索引名>;
举例
DROP INDEX Stusno_Ind;
数据查询
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] [,…]
[INTO <新表名>]
FROM <表名/视图名> [,<表名/视图名>] [,…]
[WHERE <条件表达式>]
[GROUP BY <列名1>] [HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]];
目标列表达式
目标列表达式是一个逗号分隔的表达式列表
[<表名>.]<属性列名表达式> [, [<表名>.] <属性列名表达式>] [, …]
举例
//查询单表中全体学生的学号与姓名
SELECT sno, sname FROM Student;
//查询单表中的全体学生
SELECT * FROM Student;
集函数
<集函数> ( [ DISTINCT | ALL ] * )
//集函数:SUM、AVG、COUNT、MAX、MIN
举例
SELECT DISTINCT sname, Year(GetDate())-Year(sdate) AS age FROM Student;
条件表达式
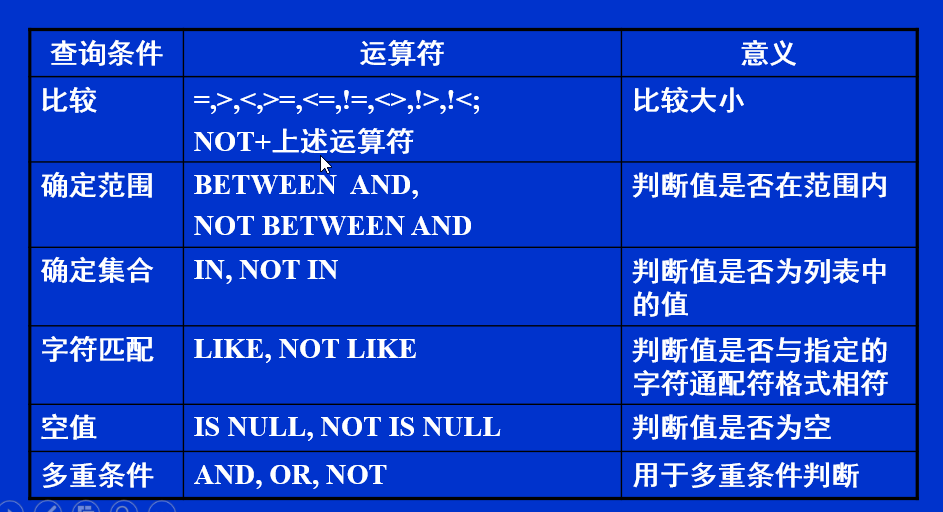 举例
举例
//从Student表中,查询男同学
SELECT * FROM Student WHERE ssex='男';
//从Student表中,查询出生日期在1980年和1990年之间的学生
SELECT * FROM Student WHERE sdate BETWEEN '1980-01-01' AND '1990-12-31';
通配符
%:百分号,代表任意长度的字符串 a%b:ab,acb,addb _:下划线,代表单个字符 a_b: acb,adb, afb
[ ]:表示中括号里面的任意一个字符 A[BCDE]表示第一个字符为A,第二个字符为B,C,D,E中的任意一个 [^ ]:表示不在中括号里面的任意一个字符 A[^BCDE]表示第一个字符为A,第二个字符为不为B,C,D,E的任意一个字符
数据操纵
数据插入——INSERT——向数据库中插入新纪录
数据修改——UPDATE——修改数据库中的某记录
数据删除——DELETE——删除数据库中的某记录
数据插入
插入元组
INSERT
INTO <表名> [( <字段1>[, <字段2>] [,…])]
VALUES (<常量1> [, <常量2>] [,…]);
举例
//将一条新学生记录(所有字段都有值)插入到表中
Insert Into S
Values (‘95020’,‘陈东’,‘男’,‘IS’,’18’);
将一条学生记录(部分字段有值)插入表中
Insert Into S(Sno,Sname)
Values (‘95020’,‘陈东’);
插入子查询 子查询不仅可以嵌套在SELECT语句中,也可以嵌套在INSERT语句中,用于生成要插入的批量数据。
INSERT
INTO <表名> [( <字段1>[, <字段2>] [,…])]
子查询;
举例
Insert Into Deptage(Sdept, Avgage)
Select Sdept, AVG(Sage)
From S Group By Sdept;
数据修改
一般格式
UPDATE <表名>
SET <字段名1>=<表达式1>[, <字段2>= <表达式2>] [,…]]
[WHERE <条件表达式>];
举例
//修改某一元组的值:如将学生95001的年龄改为22岁
Update S
Set Sage=22
Where Sno='95001';
//修改多个元组的值:如将所有学生的年龄加一岁
Update S
Set Sage= Sage+1;
//带子查询的修改语句:将信息管理系的所有学生成绩置零
Update SC
Set Grade=0
Where 'IS'=
(Select Sdept
From S
Where S.Sno=SC.Sno);
删除数据
一般格式
DELETE
FROM <表名>
[WHERE <条件表达式>];
举例
//删除某一元组:如删除学号为95001的学生记录
Delete
From S
Where Sno='95001';
//将S表清空
Delete
From S;
//带查询的删除语句:如删除信息系所有学生的选课记录
Delete
From SC
Where 'IS'=
(Select Sdept
From S
Where S.Sno=SC.Sno);
数据控制
共享程度与安全性问题的冲突 数据控制功能:
- 事务管理功能
- 数据保护功能
授予权限 一般格式
GRANT <权限> [,<权限>][,…]
[ON <对象类型> <对象名称>]
TO <用户> [, <用户>] [,…]
[WITH GRANT OPTION];
举例
//把查询S表的权限授权给用户U1
GRANT SELECT
ON TABLE S
TO U1;
//把查询S表和C表的全部权限授权给用户U1和U2
GRANT ALL PRIVILEGES
ON TABLE S, C
TO U1, U2;
收回权限 一般格式
REVOKE <权限> [,<权限>][,…]
[ON <对象类型> <对象名称>]
FROM <用户> [, <用户>] [,…]
举例
//把用户U1修改学号的权限收回
REVOKE UPDATE(Sno)
ON TABLE S
FROM U1;
//收回所有用户对表SC的查询权限
REVOKE SELECT
ON TABLE SC
FROM PUBLIC;
关系数据库设计
关系数据库设计理论
关系模式
R(U , F)
当且仅当U上的一个关系r满足F时,r称为关系模式R(U , F)的一个关系
函数依赖定义
定义:
设R(U)是属性集U上的关系模式。X,Y是U上的子集。
若R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等而在Y上的属性值不等,则称:
X函数依赖确定Y或Y函数依赖确定于X,记做X->Y。
术语:

第一范式(1NF)
每一个分量必须是不可分的数据项。 存在问题: 数据冗余;插入异常;删除异常。
第二范式(2NF)
在第一范式的基础上,每一个非主属性完全函数依赖于码。 存在问题: 插入异常;删除异常;修改复杂。
第三范式(3NF)
若关系R(U)的每个非主属性都不部分依赖于也不于传递于码,则称R(U)满足第三范式。
BCNF
- 所有非主属性对每一个码都是完全函数依赖
- 所有的主属性对每一个不包含它的码,是完全函数依赖
- 没有任何属性完全依赖于非码的任何一组属性
多值依赖

第四范式(4NF)
关系模式R<U,F>符合第一范式,对于R的每一个非平凡多值依赖,X都含有码,则称关系模式R符合第四范式
总结

关系数据库设计的步骤
- 需求分析
- 概念结构设计
- 逻辑结构设计
- 数据库物理设计
- 数据库实施
- 数据库运行和维护
需求分析
- 业务流程分析
- 数据流程分析
- 画出ER图
概念结构设计
特点:
- 能真实、充分地反映现实世界,包括事物与事物之间的联系
- 易于理解,从而可以用它和不熟悉计算机的用户交换意见
- 易于更改
- 易于向关系、网状、层次等数据模型转换
设计方法:
- 自顶向下
- 自底向上
- 逐步扩张:核心概念结构,向外扩张
- 混合策略:自顶向下和自底向上相结合
数据抽象:
- 分类
- 聚集
- 概括
任务: ER图变为数据库逻辑结构
转换原则: 实体及其属性的转换: 一个实体型转换为一个关系模式。 实体的属性就是关系的属性,实体的码就是关系的码。
1:1 可以转换为一个独立模式,也可以与任意一段的对应的关系模式合并 1:n 可以转换为一个独立模式,可以与N端对应的关系模式合并 m:n 转换为一个独立模式
设计用户子模式——视图
数据库的物理设计
- 存取方法
- 存取结构
实施与维护阶段
- 定义数据库的结构
- 数据装载/编写程序
- 数据库软件试运行
数据库安全保护
信息安全综述
安全:免于危险的质量和状态 信息安全:是对信息、系统以及使用、存储和传输信息的硬件的保护 数据库安全:是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏 访问:一个主题或对象使用、操作、修改或者影响另一个主题或对象的能力 资产:被保护的机构资源 安全蓝本:对机构里新的安全措施的实施计划 漏洞:系统内的弱点或错误,或者是使信息暴露给攻击或破坏的保护性机制
数据库安全性控制
计算机系统的安全模型
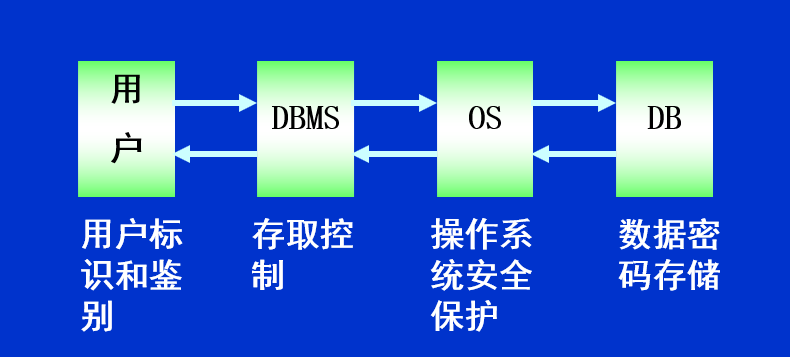
用户标识和鉴别
用户标识和鉴别是系统提供的最外层安全保护措施 举例:校园网登录
存取控制
数据库安全性主要是存取控制机制
- 定义用户权限
- 合法用户权限检查
审计
把用户对数据库的所有操作自动记录下来放入审计日志
数据加密
高度敏感性数据,需要采用数据加密技术
统计数据库安全性
在统计数据库中存在着特殊的安全性问题,需要注意。
SQL SERVER系统安全性
简要介绍,略过
版权信息
大部分内容来自于中国地质大学(北京)安海忠老师的授课PPT以及王珊,萨师煊所著的《数据库系统概论》(第四版),可在非商用-署名前提下自由分发。
更新日志
- 2015年06月12日 完成初稿
- 2015年06月14日 修复了一些格式错误