有一段时间没有写博客了,最近主要在做的是事情是重新设计并跟小伙伴 Lance 一起了实现 QingStor 对象存储的命令行工具 qsctl。经过一段时间的开发,qsctl 终于发布了首个 beta 版本,我也终于有时间能够跟大家聊一聊~~(吹嘘)~~一下这个产品。在这周五我们公司的 Think Friday 分享中,我分享了《数据驱动编程及其在 qsctl 中的实践》,本文是这次分享修改了标题并补充了部分内容后的事后总结。
大家好,我是漩涡,我是 QingStor 存储研发部的研发工程师(aka QingStor 首席 Go Template 研发工程师,逃)。我对自己的定位是效率研发工程师,我的工作职责是提升我们团队,我们的研发同事,还有调用我们服务的开发者和使用我们服务的用户的工作效率。今天的分享主要就是介绍影响我们用户工作效率的关键工具——qsctl 的重构实践。
本次分享主要分为下面六个部分:首先为不熟悉 QingStor 对象存储周边产品生态的同学介绍 qsctl 是什么,然后介绍 qsctl 在实际的运用和维护中面临的困境。接下来介绍 qsctl 2 研发初期定下的目标,然后分享 qsctl 2 是如何运用 Go 模板元编程的。在最后会介绍实践中的一些经验和最后的实际应用。
qsctl 是什么
在介绍 qsctl 是什么之前,我们需要先了解 QingStor 对象存储是什么。按照官方口径,QingStor™ 对象存储为用户提供可无限扩展的通用数据存储服务,具有安全可靠、简单易用、高性能、低成本等特点。抛开这些宣传话术,从开发者的角度来看,对象存储实际上可以视作一个通过 HTTP 接口对外提供服务的超大 Key-Value 数据库,每个文件的元数据都与它自身的内容存储在一起,只能通过一个全局唯一的 Key 来访问。
显然的,对象存储提供的接口与传统的 POSIX 接口是完全不同的,所以为了方便用户使用对象存储,除了开发各个语言的 SDK 之外,我们还需要提供各种工具:
- qsftpd: 将 QingStor 对象存储作为后端存储的 FTP 服务
- qscamel: 用于在不同的端点 (Endpoint) 中高效迁移数据的工具
- qsfs && ElasticDrive: Linux && Windows 端将对象存储挂载到本地的工具
- ...
在这些所有的工具之中,qsctl 是用户最多,也是功能最全面的,它提供了 Bucket 和 Object 创建,查看,删除的管理功能,提供了批量上传和下载 && 增量上传和下载的功能,还有类似于生成一次性访问链接这样的便利小功能。
它的使用是如此广泛,以至于它成为了 QingStor 私有云部署验收环节中的一部分:使用 qsctl 创建,查看,删除 Object 以测试服务是否正常。大量的 QingStor 对象存储用户将 qsctl 工具纳入了他们的工作流程之中:他们在各种各样的脚本中调用 qsctl 命令行来访问对象存储。
qsctl 的困境
使用如此广泛的 qsctl 从 2018 年 12 月起就再也没有任何更新了,没有新增功能,没有 BUG 修复,更别提代码重构和性能优化。Why?因为我们遇到了很多问题,人手不足固然是一方面,但是 qsctl 本身的问题才是更致命的。
首先我们遇到的是开发语言特性与日渐增长的用户需求不匹配的矛盾。
qsctl 开发始于 2016 年,对标的产品是 s3cmd,当时我们着重需要解决的问题是人有我无的问题,因此我们选择使用 Python 快速开发出一个可用的命令行工具。要知道,那时候我们甚至连一个好用的 Python SDK 都没有。我们当时对 qsctl 的期待是它能够满足用户的轻度使用需求,更加重载和生产级别的需求会引导用户基于我们的 API 来进行开发。
我们的期望是错误的。用户从来都不会以我们期望的方式来使用工具,用户从来都不会主动调用我们的 API 来进行开发。只要你提供了工具,用户就会在生产环境中使用,并将其视作服务可用性的一部分。于是大家逐渐的发现,qsctl 太慢了。单线程的上传和下载在大量小文件的场景下完全不可用,删除一个百万 Key 的 Bucket 需要好几天,为此还有用户愤怒的提交工单要求将这几天的收费全部免除。
不仅如此,Python 带来的另一个问题是静态部署很难。第一用户不一定有 Python,经常有用户提工单询问 Python 怎么安装,pip 是什么东西;第二用户不一定有我们需要的版本,有一次我修复过一个 Python 2.6 下 os.Walk 的 BUG;第三用户不一定有网络,曾经以为的 pip install 一把梭变成了支配我们很久的梦魇,逼迫我们提供一个所谓的 qsctl-offline。
除此之外,还有 Python 2 始终阴魂不散。Python 2 会在 2020 年退役,但是我怀疑一直到 2030 年,用户的 CentOS 5.x 都不会退役,我们需要一直提供 Python 2 的技术支持。
其次,我们还遇到了项目的陈旧架构不能满足复杂功能需求的矛盾。
以 Copy 为例:
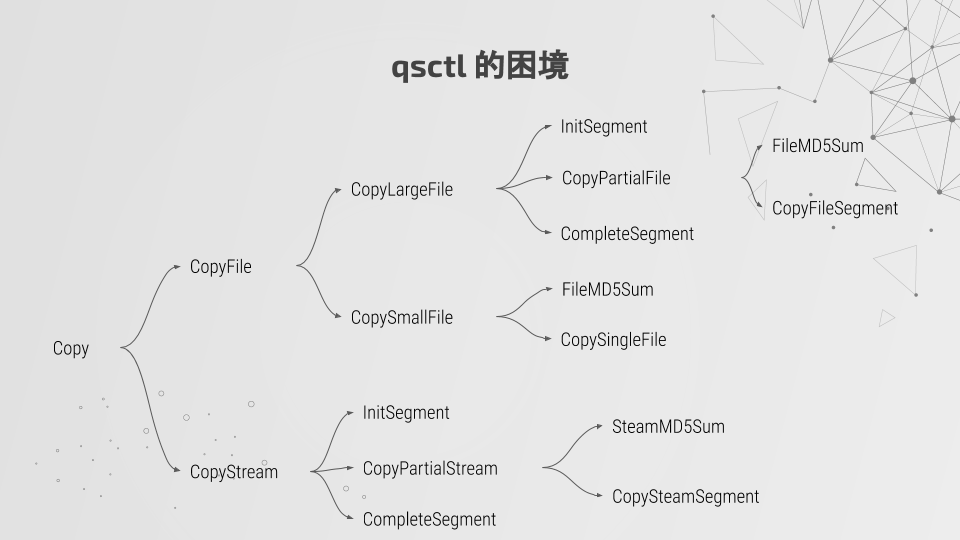
这些复杂的判断都是在一个文件中完成的,没有单元测试,没有代码覆盖率的检查,只有一个简单的脚本来测试 copy 之后文件数量是否正确。
在过去了几个月之后,我已经完全不敢去动这些代码了,更别提没有维护过 qsctl 的其他同事了。
qsctl 2 的目标
光提问题不说方案不是 QingStor 的风格,在我们团队来了一位新同事之后,我们终于下定决定重写 qsctl,彻底解决所有的历史遗留问题。现在我得到了一次机会来重新设计和实现 qsctl,我要怎么做呢?
我要做 QingStor 有史以来最棒的命令行工具。
最棒的含义是正确性,可维护性和性能兼备。在我看来,正确性是所有服务的根基,尤其是存储领域的服务。应用挂了能恢复,数据写错就是事故了。正确性决定了程序能不能用。而可维护性决定了这个程序能活多久,像旧版的 qsctl 已经在事实上死去了。在兼具了正确性和可维护性之后,我们会努力的去提升这个应用的性能。
为了保障 qsctl 2 的正确性和可维护性,我们决定采用全新的方式来开发它,也就是标题中提到的 Go 模板元编程。这次分享不会过多的涉及元编程的理论和实现,主要介绍我们的实际应用。
qsctl 2 的模板
一个最简单而朴素的想法是将所有的调用抽象为一个任务,这样我们在设计的时候就只需要考虑任务与任务之间的抽象关系,不需要考虑任务的具体实现。以初始化分段上传为例:

InitSegment 任务需要的 Input 有 PartSize,Storager 和 Path,Output 有初始化分段后得到的 SegmentID。我们首先确定有哪些任务,然后确定任务与任务之间的依赖,划分出不同的任务,之后再确定每个任务有哪些 Input 和 Output。但是我们并不把这些任务的关系通过函数调用的方式显式暴露出来,我们只提供一个任务互相调用的机制,即 《Unix 编程艺术》中所说的 提供机制,而不是策略。在这些 Value 都确定之后,我们就能够以一种统一的抽象来描述每个任务:
{
"SegmentInit": {
"description": "init a segment upload",
"input": [
"PartSize",
"Path",
"Storage"
],
"output": [
"SegmentID"
]
}
}
Type System
上层抽象已经确定,下面需要考虑如何去实现。为了保证整体服务的正确性,我们期望这个任务中的所有 Value 都是强类型的,在编译期决定的,这样我们的 IDE 和编译器就能为我们免除大量的低级错误。所以我们设计了一套类型系统:
{
"PartSize": "int64",
"Path": "string",
"Storage": "storage.Storager",
"SegmentID": "string"
}我们通过一个 JSON 文件来描述实际使用的 Type Name 和内部的类型,这样就可以通过模板来生成对应的结构体:
type PartSize struct {
valid bool
v int64
l sync.RWMutex
}我们还能够借此生成对应的 Getter,Setter 和 Validator,以 Getter 为例:
type PartSizeGetter interface {
GetPartSize() int64
}
func (o *PartSize) GetPartSize() int64 {
o.l.RLock()
defer o.l.RUnlock()
if !o.valid {
panic("PartSize value is not valid")
}
return o.v
}我们能够实现自动的加锁和解锁,还能够检查这个值是否有效,如果这个值无效,但是后续的代码中还是尝试去 Get 了,我们将其认为是开发者的问题,直接 panic 掉。不仅如此,我们还能实现任务与任务之间的 Value 自动传递:
func LoadPartSize(t navvy.Task, v PartSizeSetter) {
x, ok := t.(interface {
PartSizeGetter
PartSizeValidator
})
if !ok {
return
}
if !x.ValidatePartSize() {
return
}
v.SetPartSize(x.GetPartSize())
}Task System
在前述 Type System 的基础上,我们可以实现我们的 Task 类型了:
// SegmentInitTask will init a segment upload.
type SegmentInitTask struct {
// Predefined value
...
// Input value
types.PartSize
types.Path
types.Storage
// Output value
types.SegmentID
}由于每个 Task 的 Input 和 Output 在编译阶段就已经知道了,所以我们可以做很多事情,比如在初始化任务的时候自动载入父任务中已经存在的值:
// loadInput will check and load all input before new task.
func (t *SegmentInitTask) loadInput(task navvy.Task) {
...
types.LoadPartSize(task, t)
types.LoadPath(task, t)
types.LoadStorage(task, t)
}比如在 Task 运行之前去校验所有的 Input:
// validateInput will validate all input before run task.
func (t *SegmentInitTask) validateInput() {
if !t.ValidatePartSize() {
panic(fmt.Errorf("Task SegmentInit value PartSize is invalid"))
}
if !t.ValidatePath() {
panic(fmt.Errorf("Task SegmentInit value Path is invalid"))
}
if !t.ValidateStorage() {
panic(fmt.Errorf("Task SegmentInit value Storage is invalid"))
}
}比如自动生成这个任务的 Debug 信息:
// String will implement Stringer interface.
func (t *SegmentInitTask) String() string {
return fmt.Sprintf(
"SegmentInitTask {PartSize: %v, Path: %v, Storage: %v}",
t.GetPartSize(), t.GetPath(), t.GetStorage(),
)
}初始化和接口的实现也可以自动生成:
// NewSegmentInit will create a SegmentInitTask struct and fetch inherited data from parent task.
func NewSegmentInit(task navvy.Task) *SegmentInitTask {
t := &SegmentInitTask{}
t.SetID(uuid.New().String())
t.loadInput(task)
t.SetScheduler(schedule.NewScheduler(t.GetPool()))
t.new() // What we need to implement
return t
}
// Run implement navvy.Task
func (t *SegmentInitTask) Run() {
t.validateInput()
log.Debugf("Started %s", t)
t.run() // What we need to implement
t.GetScheduler().Wait()
log.Debugf("Finished %s", t)
}在所有的非业务逻辑代码都被自动生成之后,我们只需要专注于自己的任务即可,实现 InitSemgnet 变成一件非常容易的事情:
func (t *SegmentInitTask) new() {}
func (t *SegmentInitTask) run() {
id, err := t.GetStorage().InitSegment(t.GetPath(),
typ.WithPartSize(t.GetPartSize()))
if err != nil {
t.TriggerFault(types.NewErrUnhandled(err))
return
}
t.SetSegmentID(id)
}每个 Task 都是独立,不需要关心谁会调用它,只要实现自己的逻辑即可。这一点使得测试变得同样容易且清晰:
func TestSegmentInitTask_run(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
t.Run("normal", func(t *testing.T) {
store := mock.NewMockStorager(ctrl)
path := uuid.New().String()
segmentID := uuid.New().String()
task := SegmentInitTask{}
task.SetStorage(store)
task.SetPath(path)
task.SetPartSize(1000)
store.EXPECT().InitSegment(gomock.Any(), gomock.Any()).DoAndReturn(
func(inputPath string, pairs ...*typ.Pair) (string, error) {
assert.Equal(t, inputPath, path)
assert.Equal(t, pairs[0].Value.(int64), int64(1000))
return segmentID, nil
},
)
task.run()
assert.Equal(t, segmentID, task.GetSegmentID())
})
t.Run("init segment returned error", func(t *testing.T) {
store := mock.NewMockStorager(ctrl)
path := uuid.New().String()
task := SegmentInitTask{}
task.SetFault(fault.New())
task.SetStorage(store)
task.SetPath(path)
task.SetPartSize(1000)
store.EXPECT().String().DoAndReturn(func() string {
return "test storager"
})
store.EXPECT().InitSegment(gomock.Any(), gomock.Any()).DoAndReturn(
func(inputPath string, pairs ...*typ.Pair) (string, error) {
assert.Equal(t, inputPath, path)
assert.Equal(t, pairs[0].Value.(int64), int64(1000))
return "", errors.New("test")
},
)
task.run()
assert.False(t, task.ValidateSegmentID())
assert.True(t, task.GetFault().HasError())
})
}每个任务的测试都不需要提前设置父任务,只需要设置对应的 Input 即可。
By the way,qsctl 2.0 昨天发布了首个 Beta 版本:v2.0.0-beta.1 ,欢迎大家体验并反馈 BUG。
一些总结
这一段时间的实践带给我的是思路的转变:为实际的问题寻找一个合适的抽象,并针对抽象而不是实际的逻辑编程。模板元编程的助力在于减少试错的成本,在 qsctl 2 的开发过程中,Task System 的抽象及其实现进行过三次大规模的重构,大多数时间都花在思考和测试上,整体的业务逻辑迁移起来并不困难。
银弹当然不存在,并不是所有项目都适合搞模板元编程,但是如果你的项目中有大量的重复逻辑和确定的输入输出,不妨尝试一下。