最近一直在做面向应用的 Golang 抽象存储层,目前已经对接了十个存储后端,其中有八个是对象存储服务,可以说是对接了大部分公有云对象存储服务了。在对接的过程中有很多感慨,这次整理起来盘点一下。
截止到 v0.7.1,storage 对接了如下对象存储服务:
- azblob: Azure Blob storage
- cos: Tencent Cloud Object Storage
- gcs: Google Cloud Storage
- kodo: qiniu kodo
- oss: Aliyun Object Storage
- qingstor: QingStor Object Storage
- s3: Amazon S3
- uss: UPYUN Storage Service
每个服务会简单介绍一下,然后聊聊对应服务的 go SDK对接体验,并不涉及到性能/稳定性等方面的测试,也不是严肃的产品选型方案,请诸君明鉴。SDK 方面会统一以调用一次 Write 为例展开,看看 SDK 的设计风格和相应的错误处理体验。
azblob
如今的云计算市场上,Azure 算是比较特别的,很多服务都是自成一格,没有采取跟随 AWS 的策略:跟 AWS 把块存储,文件存储,对象存储分为三个不同的服务不同,Azure 先构建好一个 Stream Layer,然后在上面支持各种存储形态,包括 Blob,Files,Queue 和 Table,共同组成了 Azure Storage 服务。
相关 Paper: Erasure Coding in Windows azure storage
我们这次要聊的就是 Azure Blob Storage,下面简写为 azblob。
azblob 会涉及到三种资源:Account,Container 和 Blob,关系如 Azure 官方文档给出的图:
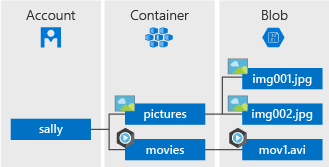
Container 对应 s3 的 Bucket,Blob 对应 s3 的 Objcet。比较特别的是 Account 的概念,Azure 通过 Account 来提供不同应用场景的优化,比如 General-purpose v2 accounts 适用于大多数场景,而 BlockBlobStorage accounts 适用于高吞吐,低延迟的场景等。
azblob 中的 blob 有三种类型,在创建的时候决定,创建后不能修改:
block blobs: 由一组 blocks 组成,单个 block 最大 100MB,最多 5W 个,也就是说单个block blobs最大 4.75 TB。page blobs: 则是由一组 512B 的 pages 组成,针对随机读写的场景优化,写操作需要对齐 512B(以 page 为单位),单次写操作最大 4MB,单个page blobs最大 8 TB。append blobs: 同样由 blocks 组成,针对 append 场景优化。单个 Block 最大 4MB,最多 5W 个,也就是说单个append blobs最大 195GB。
底层架构决定上层设计。架构复杂的情况下,API 自然也精简不起来,用户需要搞明白上述的全部内容才能在 PutBlob,PutPage,AppendBlock 和 PutBlock 这几个 API 中做出正确的选择。
azblob 提供了 container 级别的删除锁,blob 级别的写/删除锁和 snapshot,支持自定义 metadata,存储级别,批量操作,复制。支持配置 ACL,但是不支持 Blob 级别的 Policy。支持软删除,保留时间通过 DeleteRetentionPolicy 来定义,能够通过 UndeleteBlob 恢复。
azblob SDK 用来的一个突出感受是智商不太够用,一方面 SDK 对外暴露的方案跟 API 文档中给的不太对应,另一方面是 SDK 额外提供了很多抽象。比如说 put-blob 对外暴露的方法是 Upload,put-block 暴露的是 StageBlock,而 put-block-list则是 CommitBlockList。调用一次 Upload 需要初始化很多空的结构体,包括 azblob.BlobHTTPHeaders,azblob.Metadata 和 azblob.BlobAccessConditions。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
rp := s.getAbsPath(path)
...
_, err = s.bucket.NewBlockBlobURL(rp).Upload(opt.Context, iowrap.ReadSeekCloser(r),
azblob.BlobHTTPHeaders{}, azblob.Metadata{}, azblob.BlobAccessConditions{})
if err != nil {
return err
}
return nil
}返回的 Error 都统一封装为 azblob.StorageError 接口,但是不知道是不是我搞错了什么,有个蛋疼点是azblob.StorageError 暴露的 ServiceCode() 方法返回的是 ServiceCodeType ,然而 azblob 导出的是一堆 StorageErrorCodeType。所以在检查错误的时候还需要强行转换一下:
func formatAzblobError(err azblob.StorageError) error {
switch azblob.StorageErrorCodeType(err.ServiceCode()) {
case azblob.StorageErrorCodeBlobNotFound:
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case azblob.StorageErrorCodeInsufficientAccountPermissions:
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
default:
return err
}
}cos
cos 是腾讯云推出的对象存储服务,提供了 S3 兼容。
cos 有种很强的接地气的感觉,我举个例子:清单 inventory API,包括 PUT Bucket inventory,GET Bucket inventory,List Bucket Inventory Configurations 和 DELETE Bucket inventory,用来增删改查 Bucket 配置的清单,其用途是每天或者每周定时扫描用户存储桶内指定的对象或拥有相同对象前缀的对象,并输出一份清单报告,以 CSV 格式的文件存储到用户指定的存储桶中。这功能就很有意思,官方给出的基本用途也很有中国特色:审核并报告对象的复制和加密状态,简化并加快业务工作流和大数据作业。
cos 的 SDK 用起来中规中举,不过 ObjectPutOptions 下面嵌套了两个结构体 ObjectPutHeaderOptions 和 ACLHeaderOptions,稍微有那么点不太舒服,想必是 cos SDK 开发者为了能够复用 ACLHeaderOptions,不想在 API 中重复展开 ACL 相关的 Header 才如此设计的。
// Write implements Storager.Write
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
rp := s.getAbsPath(path)
putOptions := &cos.ObjectPutOptions{
ObjectPutHeaderOptions: &cos.ObjectPutHeaderOptions{
ContentLength: int(opt.Size),
},
}
...
_, err = s.object.Put(opt.Context, rp, r, putOptions)
if err != nil {
return err
}
return
} cos 同样返回了自定义的错误类型:*cos.ErrorResponse,不过并没有导出所有的 error code,需要从文档中查询对应的错误码:
func formatCosError(err *cos.ErrorResponse) error {
switch err.Code {
case "NoSuchKey":
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case "AccessDenied":
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
default:
return err
}
}gcs
GCP 充满了一股子技术精英范儿,gcs 也不例外。
他们官方文档列出来的核心功能头一条就是 Storage classes for any workload,提供了标准,近线,冷和归档四种存储级别,而且不管是哪个存储级别都能做到毫秒级的 TTFB(time to first byte),他们归档存储文档的原话是:
Unlike the "coldest" storage services offered by other Cloud providers, your data is available within milliseconds, not hours or days.
这就很强势。
gcs 同时提供了 JSON 和 XML 的 RESTful API,提供了 S3 兼容,返回的都是标准的 HTTP Status Code。API 里面都是骚东西,比如说:
compose:把一组 Object 合并为一个新 Object
rewrite:将一个 Object 重写到新位置,支持超大 Object,copy 的内部实现就是调用了一次 rewrite
gcs 的 SDK 是我见过的最酷的,抽象程度最高,也是用起来最爽的。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
rp := s.getAbsPath(path)
object := s.bucket.Object(rp)
w := object.NewWriter(opt.Context)
defer w.Close()
...
_, err = io.Copy(w, r)
if err != nil {
return err
}
return nil
}额外贴一组 gcs 和 qingstor 调用 List 方法的对比:
gcs:
for {
it := s.bucket.Objects(opt.Context, &gs.Query{
Prefix: rp,
Delimiter: delimiter,
})
object, err := it.Next()
if err != nil && err == iterator.Done {
return nil
}
if err != nil {
return err
}
}qingstor:
var output *service.ListObjectsOutput
for {
output, err = s.bucket.ListObjects(&service.ListObjectsInput{
Limit: &limit,
Marker: &marker,
Prefix: &rp,
Delimiter: &delimiter,
})
if err != nil {
return
}
marker = convert.StringValue(output.NextMarker)
if marker == "" {
break
}
if output.HasMore != nil && !*output.HasMore {
break
}
if len(output.Keys) == 0 {
break
}
}要是有机会搞 qingstor go sdk v4,我一定抄作业。
gcs 返回的错误是统一的 *googleapi.Error 类型,但是诡异的是代码中会额外处理 ObjectNotExist 的逻辑,导致在检查的时候需要额外判断:
func formatGcsError(err error) error {
// gcs sdk could return explicit error, we should handle them.
if errors.Is(err, gs.ErrObjectNotExist) {
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
}
e, ok := err.(*googleapi.Error)
if !ok {
return err
}
switch e.Code {
case http.StatusNotFound:
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case http.StatusForbidden:
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
default:
return err
}
}kodo
kodo 是七牛的云海量存储系统,提供了 S3 兼容。
kodo 的 API 设计充满了实用主义色彩,缺乏一些顶层设计,以实用为上。以同样是 Bucket 级别的几个操作为例:
设置空间标签:
PUT /bucketTagging?bucket=<BucketName> HTTP/1.1
Host: uc.qbox.me
Content-Type: application/json
Authorization: Qiniu <AccessToken>
{
"Tags":[
{"Key":xx, "Value": xx},
{"Key":xx, "Value": xx},
...
]
}设置 Bucket 镜像源:
POST /image/<BucketName>/from/<EncodedSrcSiteUrl>/host/<EncodedHost> HTTP/1.1
Host: uc.qbox.me
Content-Type: application/x-www-form-urlencoded
Authorization: QBox <AccessToken>设置 Bucket 访问权限:
POST /private HTTP/1.1
Host: uc.qbox.me
Content-Type: application/x-www-form-urlencoded
Authorization: QBox <AccessToken>
bucket=<BucketName>&private=<Private>三个 API,三种设计风格。我个人不太喜欢,但是能用。说到底,用户也不关心你的 API 设计是否优雅,能满足业务需求才是第一位的。
kodo 的 SDK 用起来感觉就很罗嗦,上传之前还需要先构造 FormUploader,然后获取 UploadToken ,Upload 方法还有一堆参数。SDK 写成这样,跟他们的 API 设计是相关的,这也是他们为了实现各种上传方式付出的代价。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
rp := s.getAbsPath(path)
uploader := qs.NewFormUploader(s.bucket.Cfg)
ret := qs.PutRet{}
err = uploader.Put(opt.Context,
&ret, s.putPolicy.UploadToken(s.bucket.Mac), rp, r, opt.Size, nil)
if err != nil {
return err
}
return nil
}kodo 返回的错误类型是 *qs.ErrorInfo,判断错误的方式也是错误码,前面的画风很正常,404 表示 not found,403 表示没权限,但是后面的一堆 6xx 和 7xx 就有点飘了,错误检查的时候也需要额外注释一下:
func formatError(err error) error {
e, ok := err.(*qs.ErrorInfo)
if !ok {
return err
}
// error code returned by kodo looks like http status code, but it's not.
// kodo could return 6xx or 7xx for their costumed errors, so we use untyped int directly.
switch e.Code {
case 404:
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case 403:
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
default:
return err
}
}oss
oss 是阿里云的对象存储服务,提供了 s3 兼容,几乎是国内的事实标准。我个人有一个不太准确的小观察是,用 s3 代称对象存储服务的客户通常都是搞国际业务的,技术范儿重一些,用 oss 代称的客户则国内用户多一些,商务范儿也重一些。
oss 的 API 中有两个特别的一点的:一个是 Put/Get Symlink,能为目标对象创建软链接。我能想到的应用场景是 GET /latest-build.tar.gz ,Key 不变,但是背后指向的 Object 一直在更新。另一个是 SelectObject,对目标文件(csv,json)执行 SQL 语句并返回结果。这个 API 是为了支持将计算下推,在存储层去做一些基本的过滤,只返回有用的数据。这样客户端这边就能减少网络流量,也能降低计算开销,对大数据平台很有利。这个还是挺酷的,目前还没有看到有厂商提供类似的功能。
oss 的 SDK 所有的 API 都接受 options ...Option 这样的参数,用户需要构造 []oss.Option 并传进去。这样的设计保证了强类型,但是无法在编译期决定 API 是否支持这个参数,依赖于用户在开发的时候好好读文档。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
options := make([]oss.Option, 0)
...
rp := s.getAbsPath(path)
err = s.bucket.PutObject(rp, r, options...)
if err != nil {
return err
}
return nil
}oss 返回了两类错误:oss.ServiceError 与 oss.UnexpectedStatusCodeError,分别对应的是有 Response Body 和没有 Body 的请求。同样没有导出错误码,需要手写:
func formatError(err error) error {
switch e := err.(type) {
case oss.ServiceError:
switch e.Code {
case "NoSuchKey":
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case "AccessDenied":
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
}
case oss.UnexpectedStatusCodeError:
switch e.Got() {
case 404:
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case 403:
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
}
}
return err
}qingstor
利益相关: 截止到本文发布时,我就职于青云QingCloud QingStor Team
qingstor 是青云QingCloud 推出的对象存储服务,提供 s3 兼容。跟其他的公有云大厂不同的是,qingstor 还有很多私有云客户。
功能上基本对标 s3,多了 AppendObject, MoveObject 和 FetchObject。受累于青云QingCloud 本身至今没有对标 AWS Lambda 的产品,qingstor 被迫自己实现了图片转码和音视频转码等功能。按照我的看法,这些功能本应该从对象存储这一层剥离出去的。
qingstor 的 SDK 开发很大程度上参考了 s3 的 go SDK,同样采用了代码生成的方式来保证每个 API 的 Input 和 Output 结构都是确定的。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
input := &service.PutObjectInput{
ContentLength: &opt.Size,
Body: r,
}
...
rp := s.getAbsPath(path)
_, err = s.bucket.PutObject(rp, input)
if err != nil {
return
}
return nil
}qingstor SDK 返回了专门的 QingStorError 类型,同样没有导出 error code:
func formatQingStorError(e *qserror.QingStorError) error {
if e.Code == "" {
switch e.StatusCode {
case 404:
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, e)
default:
return e
}
}
switch e.Code {
case "permission_denied":
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, e)
case "object_not_exists":
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, e)
default:
return e
}
}s3
s3 想必是不用多说了,对象存储领域的事实标准。除了 s3 本身以外,本文聊到了 7 家公有云对象存储服务供应商,只有 azblob 没有直接兼容 s3 接口。私有云领域的 ceph 和 minio 则更是早早的就提供了 s3 接口的兼容,并将其作为自己的重要卖点。
在我看来 s3 的最大优势在于它与 AWS 平台的深度协作,能够作为诸多 AWS 产品的备份/恢复解决方案,能集成于各种大数据解决方案,能够与 Lambda 协同实现各种各样的功能。产品生态恐怖如斯,后来者只能努力兼容 API 来稍微喝点汤。
s3 SDK 有着很明显的代码生成痕迹,所有参数都放在一个 Input 中。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
rp := s.getAbsPath(path)
input := &s3.PutObjectInput{
Key: aws.String(rp),
ContentLength: &opt.Size,
Body: aws.ReadSeekCloser(r),
}
...
_, err = s.service.PutObject(input)
if err != nil {
return err
}
return nil
}
s3 SDK 返回了 awserr.Error 类型,同样是没有导出的错误码:
func formatError(err error) error {
e, ok := err.(awserr.Error)
if !ok {
return err
}
switch e.Code() {
case "NoSuchKey":
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case "AccessDenied":
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
}
return err
}uss
uss 是又拍云提供的对象存储服务,是我遇到的头一个不能通过 API 创建 Bucket,有真正的目录层级的对象存储服务。与其说是一个对象存储服务,倒更像是一个通过 HTTP 接口访问的文件存储。
uss 提供的 API 相对弱一点,只有文件和目录的操作,没有提供类似于 ACL,Policy 这样的特性。
func (s *Storage) Write(path string, r io.Reader, pairs ...*types.Pair) (err error) {
...
rp := s.getAbsPath(path)
cfg := &upyun.PutObjectConfig{
Path: rp,
Reader: r,
}
err = s.bucket.Put(cfg)
if err != nil {
return err
}
return
}uss 的错误处理就很难搞了,在展示 storage 怎么处理 uss 的错误之前,可以先看看它的源码是怎么写的:
resp, err := up.doHTTPRequest(config.method, url, headers, config.httpBody)
if err != nil {
// Don't modify net error
return nil, err
}
if resp.StatusCode/100 != 2 {
body, _ := ioutil.ReadAll(resp.Body)
resp.Body.Close()
return resp, fmt.Errorf("%s %d %s", config.method, resp.StatusCode, string(body))
}我现在真的是有很多问号,API 都已经返回确定结构的 JSON 了,为啥 SDK 还要偷这个懒?Unmarshal 一下不吃亏的吧?最气的是,SDK 里面直接把 Body 读完了,外面想处理都没有机会了,食我 error string 啦!
func formatError(err error) error {
fn := func(s string) bool {
return strings.Contains(err.Error(), `"code": `+s)
}
switch {
case fn("40400001"):
// 40400001: file or directory not found
return fmt.Errorf("%w: %v", services.ErrObjectNotExist, err)
case fn("40100017"), fn("40100019"), fn("40300011"):
// 40100017: user need permission
// 40100019: account forbidden
// 40300011: has no permission to delete
return fmt.Errorf("%w: %v", services.ErrPermissionDenied, err)
default:
return err
}
}总结
本文吐嘈了八家公有云对象存储供应商,其中 5 家国内的,3 家国外的。还是能比较明显的看出国外的三个大厂搞的对象存储各有特色,SDK 也写的非常扎实。国内的对象存储供应商里面 oss 独一挡,不仅能追赶上御三家的节奏,还能拿出点自己的干货,uss 吊车尾,功能不完整,SDK 一托屎。其他的厂商都差不多,都有些自己的问题。
这个八个供应商里头,5 个巨头,3 个创业公司。不难发现这个 5 个巨头设计的 API 一致性都很强,SDK 也都写的不错。创业公司受限于人手和生存压力,往往没有办法顾及那么多,不管是 API 的设计还是 SDK 的开发优先级都不是最高的,尽力满足用户需求,生存下去才是第一位的。
我们 QingStor 搞存储真的算挺认真的了(
PS
- 本文单纯是 storage 开发过程中的体验吐嘈,文中提到的问题都是开发过程中的真实体验
- 没有提及的厂商都是由于我个人尚不了解导致的,并非刻意排除
- 如有错漏都是我个人对文档的理解有误,欢迎指正