CORFU 是 Clusters of Raw Flash Units 的缩写,同时也是希腊靠近 Paxos 的一个小岛(比 Paxos 大不少)
图中右下角就是 Paxos 岛,而左上角那个巨无霸就是 Corfu 岛
正如它的全名所暗示的,CORFU 等价于一个分布式 SSD 集群,面向客户端提供了追加写和基于偏移的随机读取操作。本文将会详细介绍 CORFU 的设计思路和实现,CORFU 论文中的应用实现和性能分析将会被省略。
CORFU 主要分为两部分:存储服务器 (Storage Server) 与客户端 (Client)。Storage Server 会将它连接的 SSD 设备分为多个物理上的 Page,并维护 addr 到实际 page 的映射。而 Client 则会维护日志中最小单元——position 到多个 < serv / addr > 的映射(CORFU 将其叫做 Projection),并对外暴露 API。
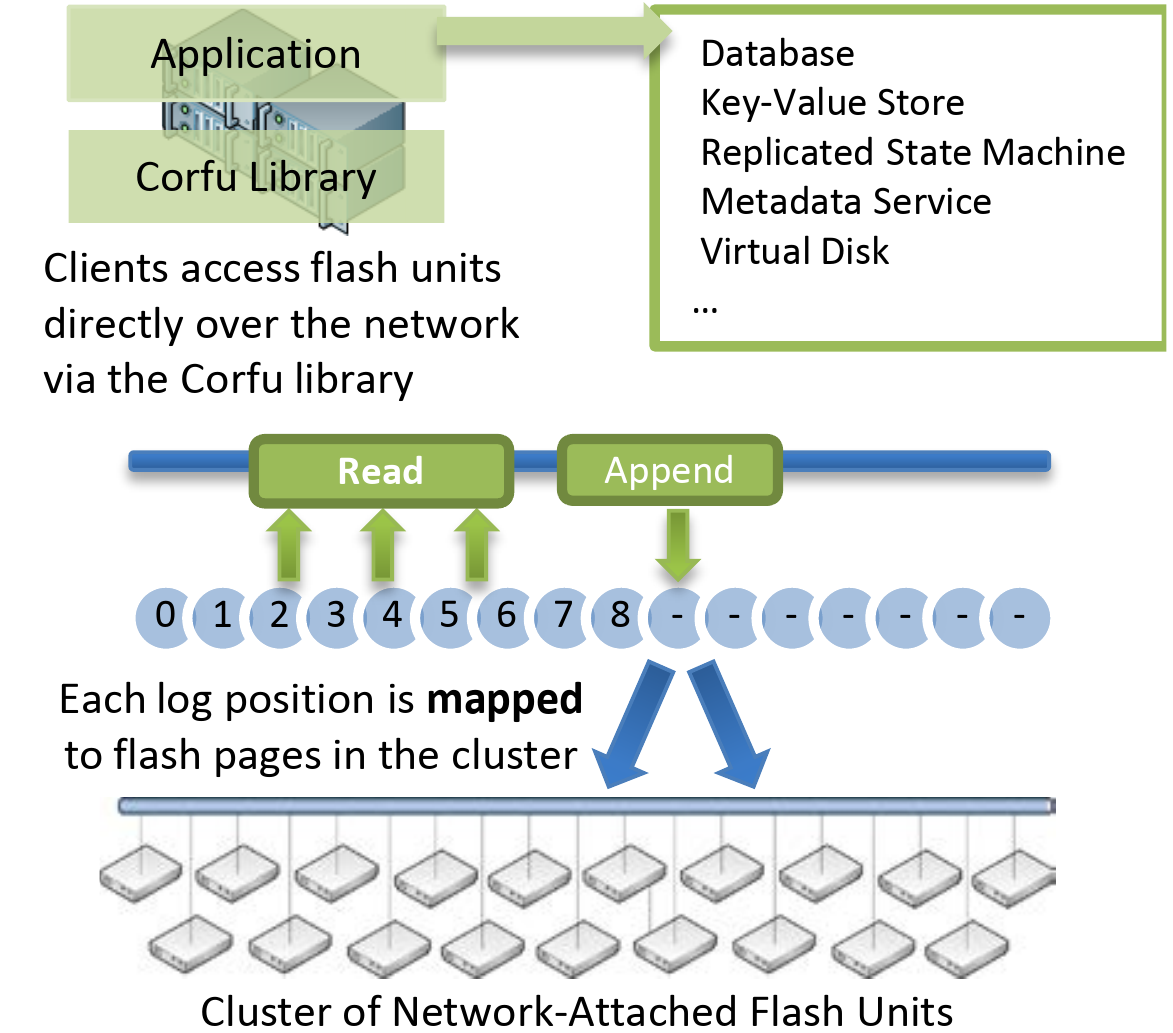
为了提高整个系统的吞吐,不管是 Storage Server 还是 Client 彼此之间都不会进行通信,也没有感知。CORFU 选择将大部分的逻辑都放在了 Client 端,Client 需要自行确定下一个 Append 所使用的 offset,需要自行维护最新的 Projection,需要处理数据的 replication。将复杂性推到了 Client 端之后,CORFU 的 Storage Server 可以非常简单,以至于能够在 FPGA 上实现。
在论文的后半部分,作者给出了两种存储单元的组织形式,一种是传统的服务器,上面有一组 SSD;另一种是自己定制的设备,由 FPGA ,网络接口和 SSD 组成,Storage Server 的功能和网络协议完全由硬件实现。
在了解了整体的结构之后,我们从下往上看看 CORFU 是如何设计,做了哪些 trade off。
存储单元
CORFU 存储单元最核心的需求是实现 write-once 语义,为此 CORFU 明确规定了 read,write 的行为:
- read
- 给定的位置还没有写入,则返回错误
err_unwritten - 给定的位置已经被写入了,则返回数据
<page-content>
- 给定的位置还没有写入,则返回错误
- write
- 给定的位置已经写入了,则返回错误
err_written - 给定的位置可用,则写入数据并返回
ACK
- 给定的位置已经写入了,则返回错误
因为只能 write-once,为了能够实现空间的 GC,所以存储单元还需要支持 delete:
- delete
- 将给定的位置标记为
deleted并返回ACK
- 将给定的位置标记为
read 和 write 的行为也需要做相应的调整:
- read
- 给定的位置已经被标记删除了,则返回错误
err_deleted
- 给定的位置已经被标记删除了,则返回错误
- write
- 给定的位置已经被标记删除了,则返回错误
err_deleted
- 给定的位置已经被标记删除了,则返回错误
为了能够将被标记删除的 Page 进行回收,CORFU 还提出存储单元需要维护一个 watermark 值,要求小于这个值的地址都必须写入过(可能的状态是 written 或 deleted),并从存储单元 addr->page hashmap 中删除那些被标记删除且小于 watermark 的 addr。如果后来的请求要访问小于 watermark 又不在 addr->page hashmap 中,存储单元直接返回 err_deleted 即可,因为这个 addr 肯定已经被删除了。在 addr 被删除之后,存储单元可以将 free 的 page 重新分配为更高的 addr 以实现空间的回收利用。
此外,为了能够支持 Client 端 Projection 变更,存储单元还需要能够理解当前 Projection 的状态。CORFU 的做法是在存储单元处维护一个 epoch,同时 Client 所有的请求中都会携带 epoch,如果 Client 请求中的 epoch 与本地存储不匹配,则直接返回 err_sealed 错误。Cilent 收到这个错误就会触发 RECONFIG,并在成功后自增 epoch。
Projections
为了避免读写请求中出现 Client 之间的相互通信,CORFU 要求 Client 通过其他的一致性协议(原文是 any black-box consensus-engine)来协商出一份全局的 Projection。CORFU 将所有 position 分为多个 range,当前活跃的 range 被命名为 active range,只有在 active range 中才会出现 write 操作;每个 range 中的 position 按照某种确定的算法进行分配,比如 round-robin。这样所有 Client 都能够直接访问存储单元,从而最大化整体系统的吞吐量。特别的,每个 postion 对应的并不是单个 < serv / addr >,而是两个或多个,他们之间彼此互为镜像。
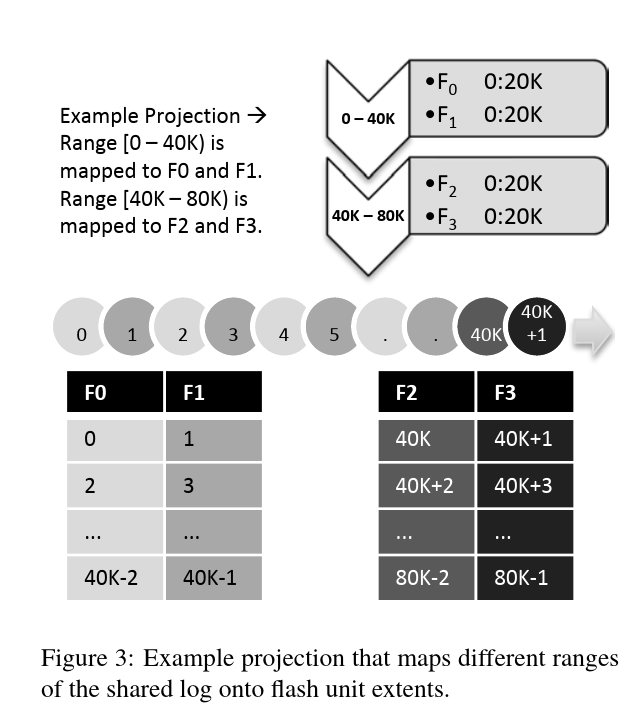
Projection 不可避免的会发生变更:存储单元挂了,当前 active range 已经写满等等,CORFU 需要支持 Projection 的变更。正如在存储单元的最后一段提到的那样,Client 会维护一个本地的 epoch 并在收到 err_sealed 时触发 RECONFIG。
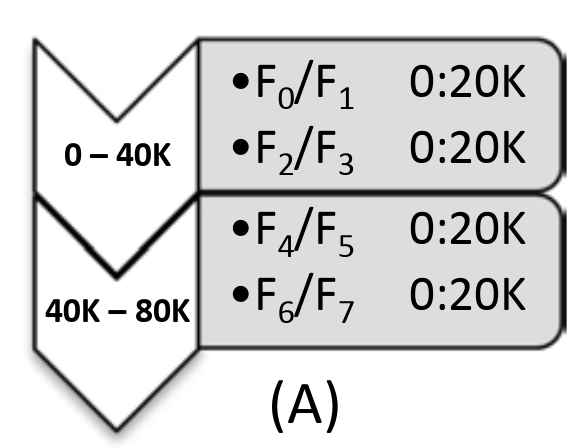
假设现在有 F0 ~ F7 这 8 个存储单元,其中 F0/F1 表示 F0 与 F1 是同一个 postion 的 mirror。集群写入到 50K 时,F6 存储单元的硬盘突然被 (总理) 拔了出来。在检测到 F6 挂了之后,CORFU 会将 F8 加入 Projection。
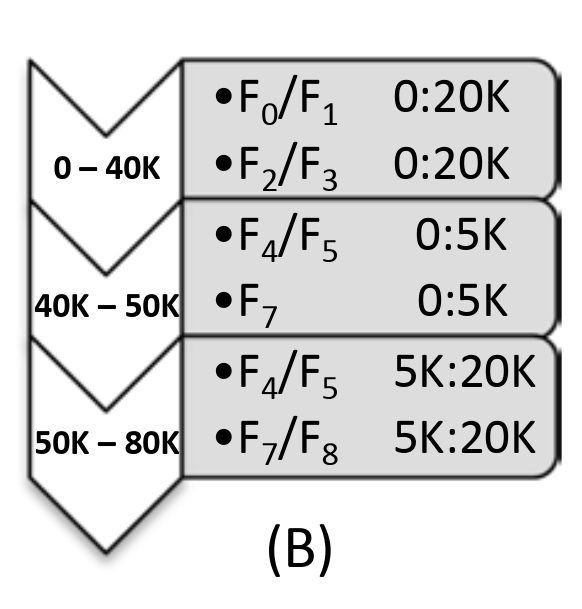
此时 F8 能够用于服务 50K 之后的读写,同时 F8 会尝试从 F7 读取之前的数据以恢复副本的数量。如果有 Client 的 Project 还没有更新,请求到了故障的 F6,F6 则会返回错误并使得 Client 主动去更新自己的 Projection。当 F8 重建完毕时,Projection 的状态会如图 C 所示:
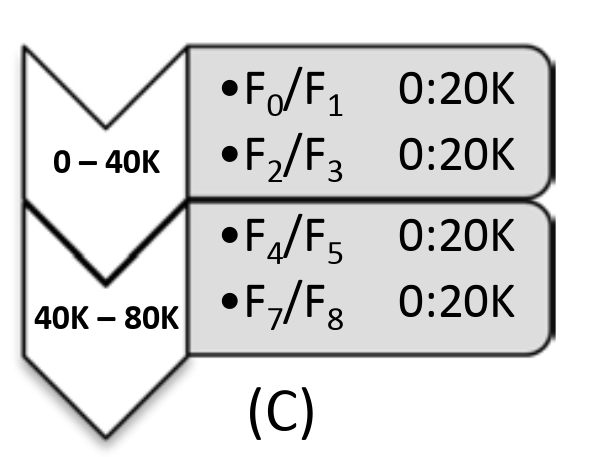
F8 已经完全替换掉了 F6。随着读写的继续,当程序已经写到 80K 时,CORFU 则会增加一个新的 range 并将 Projection 切换到 D:
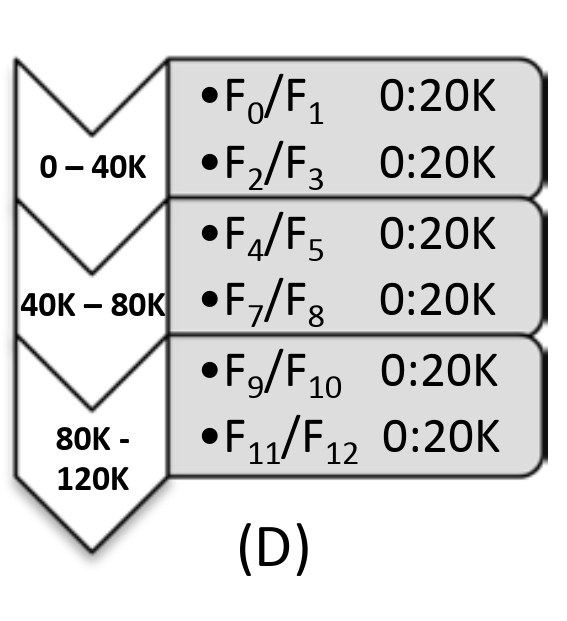
根据论文中的评估,出现磁盘故障时,CORFU 能够在 30 ms 内恢复。
Client
CORFU 通过 Client 对外暴露了如下 API:
- append(b): Append entry b 并且返回 postion l
- read(l): 读取 postion l 的 entry
- trim(l): 提示在 postion l 处已经没有有效的数据
- fill(l): 强迫完成在 postion l 处的 append
append,read 和 trim 的含义都比较显而易见,但是 fill 会难懂一些:为了理解 fill 的存在,我们需要从最朴素的 append 谈起。
比较敏锐的读者可能已经发现了,按照前文中展示的逻辑,Client 的 append 性能会极其底下:假设服务刚刚启动,所有的 Client 都在竞争 position 0 处的 append,最终只有一个 Client 会成功写入,其他的 Client 会收到 err_written 错误。为了缓解这个问题,CORFU 引入了一个新的组件:Sequencer。
Sequencer 是一个简单的计数器,它对外提供一个形如 get_next_offset 的接口,不停的自增内部维护的计数器并返回。Client 在发起 append 时会首先向 Sequencer 请求一个可写入的 offset。Sequencer 的地址会被记录在 Projection 中,当 Projection 发生改变的时候,Sequencer 也会一同更新。为了使 Sequencer 能快速回复,存储单元也提供一个新的接口:seal,当存储单元收到 seal 请求时更新自己的 epoch 并返回自己是否已经被封存和自己本地最大的 addr。在 Client RECONFIG 时会一并恢复 Sequencer 的值。
但是这会带来另外一个问题:Hole。假设 Client 从 Sequencer 拿到了一个 offset,但是因为某些故障导致它并没有能够完成写入,此时 Log 中就会出现一个空洞,从而影响上层应用。CORFU 提供的解决方案是为应用程序暴露了 fill 接口,允许他们激进的处理这些空洞,同时还调整了存储单元的行为:当 write 返回错误 err_written 时,存储单元还会返回该 page 的 content。
CORFU 的 append 采用了某种形式的 Chain Replication,保证所有的副本都会以特定的顺序写入,因此失败的情况只会有以下两种:
- 部分副本写入失败:fill 会将写入成功的副本返回的
err_written中携带 content 写入那些失败的副本,从而实现了 append redo - 所有服务写入失败:fill 会将
err_junk写入存储单元,存储单元会对err_junk做特别处理,此时的 addr 会指向一个特别的指针,并不会真的落盘
所以完整的 CORFU 协议如下图所示:

Fault Tolerance
作为一个分布式系统,容错是最重要的部分。CORFU 考虑了如下几个问题:
- 为了降低存储成本,提高容错能力,CORFU 要求 f+1 个节点能够挂掉 f 个,这就要求不能使用基于多数派的算法
- 为了尽可能减少对存储单元的要求,CORFU 要求逻辑都在 Client 端实现,存储单元互相不要进行通信
- 实现快速读取,要求 Client 只访问一个副本就能获取数据
为此,CORFU 采用了一个客户端驱动的 Chain Replication 变体:
- 当 Client 发起 wirte 请求时,client 会按照特定的顺序来逐个更新,只有存储单元返回 ACK 时才会进行下一个
- 当 Client 发起 read 请求时,client 会请求 Replication Chain 中的最后一个存储单元来获取数据。
- 有一个优化是如果 Client 明确的知道某个 postion 已经写入成功了,那它可以请求任意一个副本
CORFU 总结了三种故障类型:
- Client 在 Append 时失败:由应用程序主动调用 fill 来修复空洞
- 存储单元故障/离线:Client 发起 RECONFIG
- 客户端可能无法读取数据,即使这个 postion 已经被写成功了
- 网络出现了分区导致某个存储单元离开,而部分客户端也在这次分区中跟这个存储单元一起离开了,此时就会出现某个 position 已经在新的 projection 中写入完成了,但是客户端还在从旧的 projection 的存储单元中读取数据,这就会出现不符合预期的
err_unwritten。 - CORFU 给出了多种解决方案,比较可行的一种是
lease,存储单元需要维护一个心跳来定期更新租约,否则就视作故障从而触发主动的 RECONFIG。
- 网络出现了分区导致某个存储单元离开,而部分客户端也在这次分区中跟这个存储单元一起离开了,此时就会出现某个 position 已经在新的 projection 中写入完成了,但是客户端还在从旧的 projection 的存储单元中读取数据,这就会出现不符合预期的
总结
CORFU 是一个面向 SSD 设计以客户端为中心的 Shared Log 实现,能够用来实现 KV 存储,状态机复制和各种分布式数据结构。CORFU 的优势是不需要对数据做 Sharding(当然本质上是按照时间进行 Sharding),可扩展性强,读取速度快,不会被单机的 IO 瓶颈限制。缺点是写入的时候需要写一个完整的 Chain Block,延迟相对较高,面向吞吐而不是延迟优化,应用层需要自行处理空洞。
参考资料
- CORFU 在不同的地方发表过,主要的思想基本都是一致的
- the morning paper 的介绍值得一看
- @nan01ab 同样给出了对论文内容的介绍: CORFU -- A Shared Log Design for Flash Clusters
- TOCS13' CORFU: A Distributed Shared Log 在知乎专栏的这篇文章给出了高度的概括