今天从数据操作接口的角度聊聊各种各样的持久化存储服务,根据数据的定位方式,我将这些服务分为以下几类:
- Byte Storage:基于字节定位(寻址) 生造词汇,非专业术语
- Block Storage/块存储:基于块的偏移(block offset)定位
- File Storage/文件存储:基于文件的路径(file path)定位
- Key-Value Storage/键值存储:基于数据的键定位
- Object Storage/对象存储:基于对象的键(object key)定位
- Content Hash Storage/内容哈希存储:基于内容的哈希(content hash)定位 生造词汇,非专业术语
从更广泛的角度来说,数据库(无论是 SQL,NoSQL 还是 NewSQL)也是存储系统的一种,用户通过特定的接口,比如SQL,来存取其中的数据。我对数据库所知甚少,就不展开详细聊了。此外,在各类存储的时候我都会使用 Linux 平台下的接口举例,其他平台应当有与之类似的接口,故不赘述。
Byte Storage
Byte Storage 是我生造的词汇,业内更常用的说法叫做 PMEM(Persistent Memory) 持久化内存,也叫做 NVM(Non-Volatile Memory) 非易失性内存。
传统上认为的计算机存储架构如下:
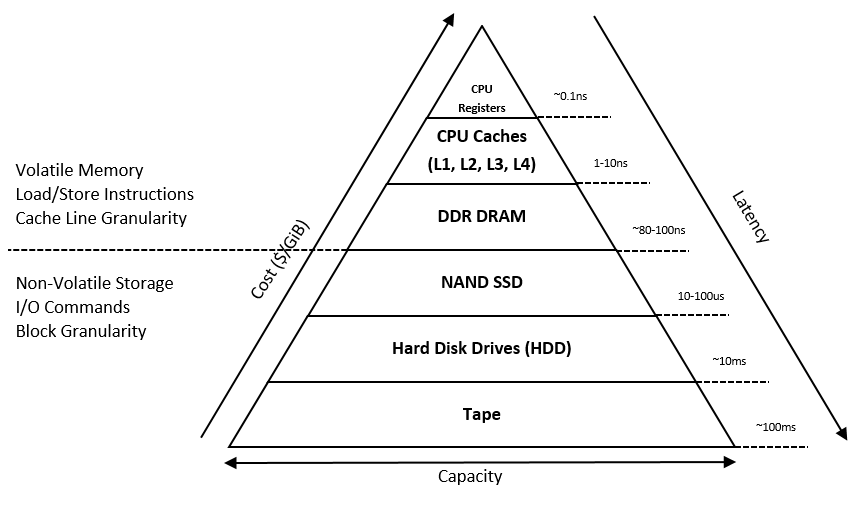
自上往下延迟延迟逐渐增加,在横线往上是易失性内存,往下是非易失性存储。不难发现横线处出现了一处延迟的跃增:从 DRAM 的 80100ns 突增到了 SSD 的 10100us。PMEM 就是为了弥补这一鸿沟而存在的:他在具备数据持久化能力的同时能够提供 1us 内的延迟。
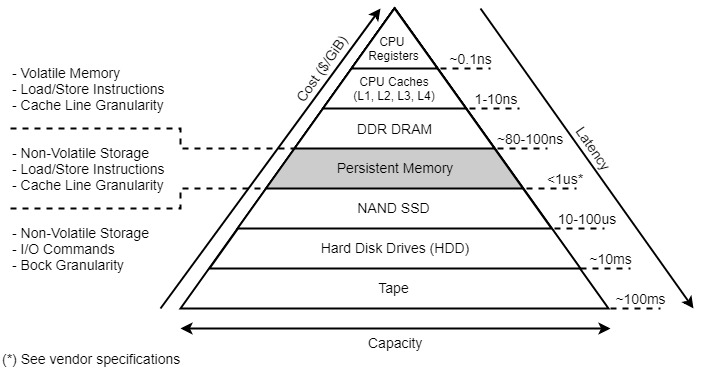
于是 PMEM 就为业界带来了一种全新的存储类型:Byte Storage,应用可以操作字节级别的数据,而不需要考虑 Block 对齐。目前调用 Byte Storage 的相关接口需要使用 Persistent Memory Development Kit (PMDK),其中 libpmem2 接口看起来大概是这样
PMEM 也能够简单的当做一个更大的内存使用,在这种场景下应用是无感知的,以后有机会再来介绍。Byte Storage 接口是相当底层的,在进行相关的研发之前需要仔细阅读 SNIA 提出的 NVM Programming Model (NPM)。
Byte Storage 通常有如下特性:
- 按字节定位数据,不目录结构
- 支持 Byte 级别的随机读写
Block Storage
Block Storage 块存储对外暴露的是 Block 级别的 API,跟 Byte Storage 的区别在于 Block 要比 Byte 大的多,其大小通常由操作系统确定。
操作系统内存管理中通常会存在 page 的概念,它是固定长度的内存块,在物理和虚拟内存寻址中都是连续的,是操作系统进行内存分配的最小的数据单位,在现代 Linux 操作系统中通常为 4KB,同时 page size 也是 block size 的上限。在存储设备底层的最小可寻址单元叫做扇区(sector),通常为 512B,这是 block size 的下限。值得注意的是,512B 的扇区是硬盘设备向操作系统提供的抽象。在物理介质上,现代的大容量硬盘会使用更大的扇区大小,比如 4K。为此大家通常把前者叫着 “逻辑扇区”,后者叫做 “物理扇区”。早年经常装机的同学口头说的 分区 4K 对齐 指的就是在分区的时候将他们对齐,从而避免读写性能的下降,现在的操作系统在硬件设备支持的情况下可以开启原生的 4K Sector 支持。
以 Linux 的存储栈为例:

来自上层的 I/O 请求经过种种抽象后最后会统一交由 Block Layer 处理。在这一层,请求会被构造为一个个的 bio 结构体,该结构体会携带目标设备的 ID,设备上的偏移(需对齐至 Block Size),大小以及缓存区的内存地址。这些 bio 请求在经过调度器的排列之后会发送给存储设备驱动,并最终落到存储设备上。
为了提升单机的扩展能力,人们通常使用 SAN(Storage Area Network) 来连接服务器和外置存储设备,相对的,原来那种直接连接存储设备的方式就被叫做 DAS(Direct-attached storage)。DAS 与 SAN 相关的接口,协议和实现繁多而复杂,我们以后有机会再聊,此处就不展开了。
块存储通常有如下特性:
- 通过 Block 偏移定位数据,不目录结构
- 对单个 Block 不支持随机读写,只能整块写入或删除
File Storage
File Storage 文件存储对外暴露的是 File 级别的 API,应用通过文件的路径来定位文件。接口层面通常是指 POSIX(Portable Operating System Interface) 中定义的文件与目录相关的操作,比如 open, readdir 等。此外,业界中也存在非 POSIX 语义或者弱化 POSIX 语义的文件存储服务,前者有 Azure Files REST API 支持通过 RESTful API 来操作文件,后者有 HDFS (The Hadoop Distributed File System) 提供了弱化版本的 POSIX 语义保证,比如仅支持 Append 写入等等。根据 基于文件的路径(*file path*)定位 的定义,我们一并算作是文件存储服务。
Linux 为文件存储暴露的抽象叫做 VFS(Virtual file system):
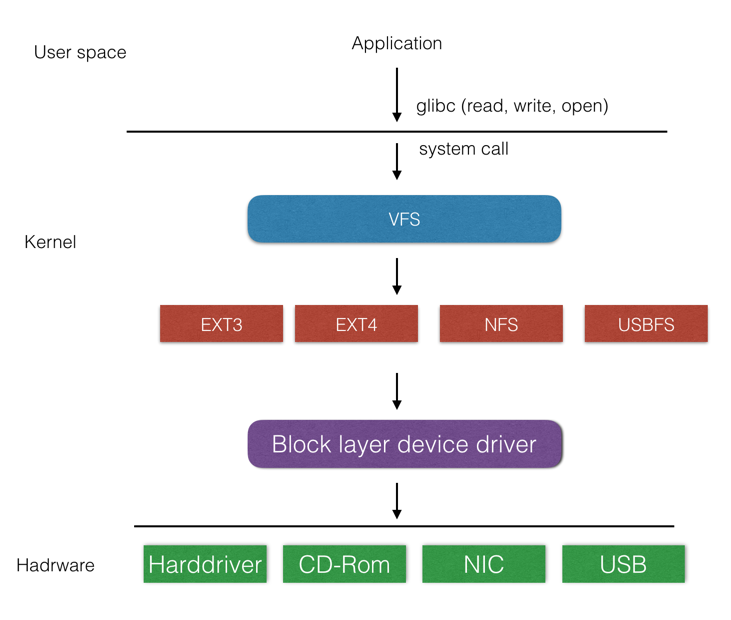
基于 VFS,Linux 向下为各种文件系统提供了需要实现的接口,向上暴露了各种用于文件操作的系统调用,比如说 Golang 中的 f.ReadDir() 实际上内部就是调用了 readdir(实际上是 getdents) 与 lstat 等系统调用。直接基于 VFS 实现文件系统需要开发内核模块,一般称之为内核态文件系统,优点是能够减少内核态与用户态之间的切换,缺点是开发与部署较为困难,业界更为普遍的方案是开发用户态文件系统。
一种方案是基于 Linux 的 FUSE(Filesystem in Userspace) 机制,它主要由内核模块 fuse.ko和用户态的库 libfuse两部分组成:
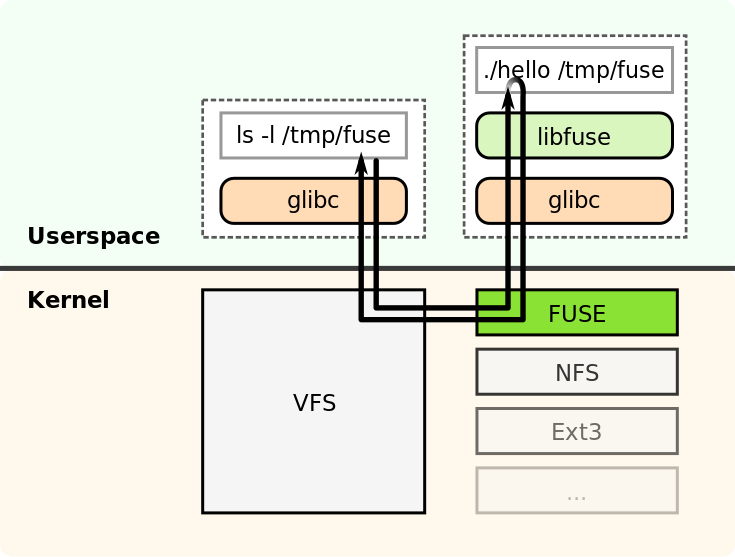
用户只需要实现 libfuse 中要求的函数,就能够实现一个基于 FUSE 的文件系统。
另一种方案是基于网络文件协议开发,这种方式也就是我们通常所说的 NAS(Network-attached storage),常见的网络文件协议包括 NFS,SMB 等等。Linux 内核中提供了 nfsd 作为 NFS 的 client daemon 实现,同时社区也开发了用户态的 NFS Daemon nfs-ganesha。
文件存储通常有如下特性:
- 通过路径定位数据,存在目录结构
- 支持随机读写
- 支持 Append 等操作
Key-Value Storage
Key-Value Storage 对外暴露的是 Key-Value 的 API,应用通过数据的 Key 来定位。传统上这类存储我们一般划入数据库领域而非存储领域,比如说 redis 和 tikv。但是近年来越来越多的厂商尝试在底层的存储设备上直接提供 Key-Value 的接口,比如说三星与 SNIA 联手推出的 KVSSD 已经成为了标准,并进入了最新的 NVMe 2.0 规范 中。
键值存储通常有如下特性:
- 通过 Key 定位数据,不存在目录结构
- 不允许修改,只能覆盖
- 不支持随机读写
Object Storage
Object Storage 对象存储对外暴露的则是 Object 级别的 API,应用通过 Object 的 Key 来定位文件。接口层面通常指事实标准 AWS S3 RESTful API 接口,比如 GET /object 以下载,PUT /object 以上传等。在 S3 标准之外,各大厂商也有自己的原生 API 接口,比如 Google Cloud Storage 和 Azure Blob Service。此外,也存在通过其他传输协议的对象存储服务,比如 Ceph RADOS 使用自行设计的网络协议暴露对象的接口,通过 librados 调用。
与之前提到的各种存储不同的是,Object Storage 并没有业界的统一标准。目前的事实标准是 S3 的 HTTP 接口,SNIA 提出了一套 CDMI(Cloud Data Management Interface) 接口(跟 S3 接口很相似),但是并没有多少人支持。所以接入各家的对象存储服务需要使用他们的 SDK,比如 aws-sdk-go。
对象存储通常都有如下特性:
- 通过 Object 的 Key 定位文件,不存在目录结构,可以通过指定
delimiter = "/"模拟目录 - 写入后的 Object 不允许修改,只能覆盖
- 不支持随机写入,可以通过指定
Range来进行随机读取 - 部分服务可能会支持 Append 操作
- 支持的文件通常较大,比如 S3 支持单文件 50TB
Content Hash Storage
Content Hash Storage/内容哈希存储是我生造的又一个词汇,指通过内容哈希来定位数据的存储服务。IPFS 是这类服务的典型实现,用户需要使用 CID(Content Identifiers) 来存取数据,IPFS 称之为 Content addressing。
这类存储通常是用来满足像区块链这样对数据完整性要求高的场景,在网盘的实际应用中也经常会抽象出类似的接口来保障数据的完整性。比如使用数据的 SHA256 哈希结果作为 Key 进行存储,在读取时进行 Hash 的校验等。从实现上来讲,Content Hash Storage 必须依赖其他接口形式的存储作为底层数据的实际存储,目前暂时没有能直接提供类似抽象的硬件设备。
Content Hash Storage 通常有如下特性:
- 使用写入内容的 Hash 寻址,不存在目录结构,但是通过引入更上层的应用逻辑来模拟
- 写入后的 Object 不允许修改,修改后 Hash 也会发生变化
- 不支持 Append 等操作
总结
本文从数据操作接口的角度讨论了各种各样的持久化存储服务:
- Byte Storage:基于字节定位(寻址)
- Block Storage/块存储:基于块的偏移(block offset)定位
- File Storage/文件存储:基于文件的路径(file path)定位
- Key-Value Storage/键值存储:基于数据的键定位
- Object Storage/对象存储:基于对象的键(object key)定位
- Content Hash Storage/内容哈希存储:基于内容的哈希(content hash)定位
在理解这些服务时,我们需要注意以下几点:
- 不能把存储服务的接口与底层的存储介质对等起来:就像在 Key-Value Storage 一节我们讨论的,硬件厂商也正在块设备的层面直接提供更高级的 KV API,以避免额外的开销。
- 不能将存储服务的接口与底层的技术实现相捆绑:未来我们还会详细介绍 Ceph 等服务,我们会发现他在 RADOS 对象存储接口上实现了块,文件和对象等多种存储接口,而 RADOS 的底层却又有着
FileStore,BlueStore等分别使用文件存储和块存储接口的实现。 - 不能将存储服务的接口与底层硬件接口 & 协议相混淆:块存储不一定是本地的,对象存储也不一定要走 HTTP。
希望本文能够帮助大家更好的理解各种各样的存储服务及其背后的本质特征,欢迎在评论区一起讨论~
参考资料
- Persistent Memory Overview 是来自 pmem.io 的文档
- 持久化内存调研 非常清晰的介绍了 PMEM
- The Block I/O Layer
- Linux Storage Stack Diagram
- @farseerfc 的 柱面-磁頭-扇區尋址的一些舊事 非常精彩
- Wikipedia: Storage area network
- Overview of the Linux Virtual File System
- @kenshinx insight-into-linux
- Writing a Kernel Filesystem
- io_uring 的接口与实现
- FUSE 的介绍
- Wikipedia: Network-attached storage
- Wikipedia: Network File System
- Wikipedia: Server Message Block
- The Key to Value:Understanding the NVMe Key-Value Standard