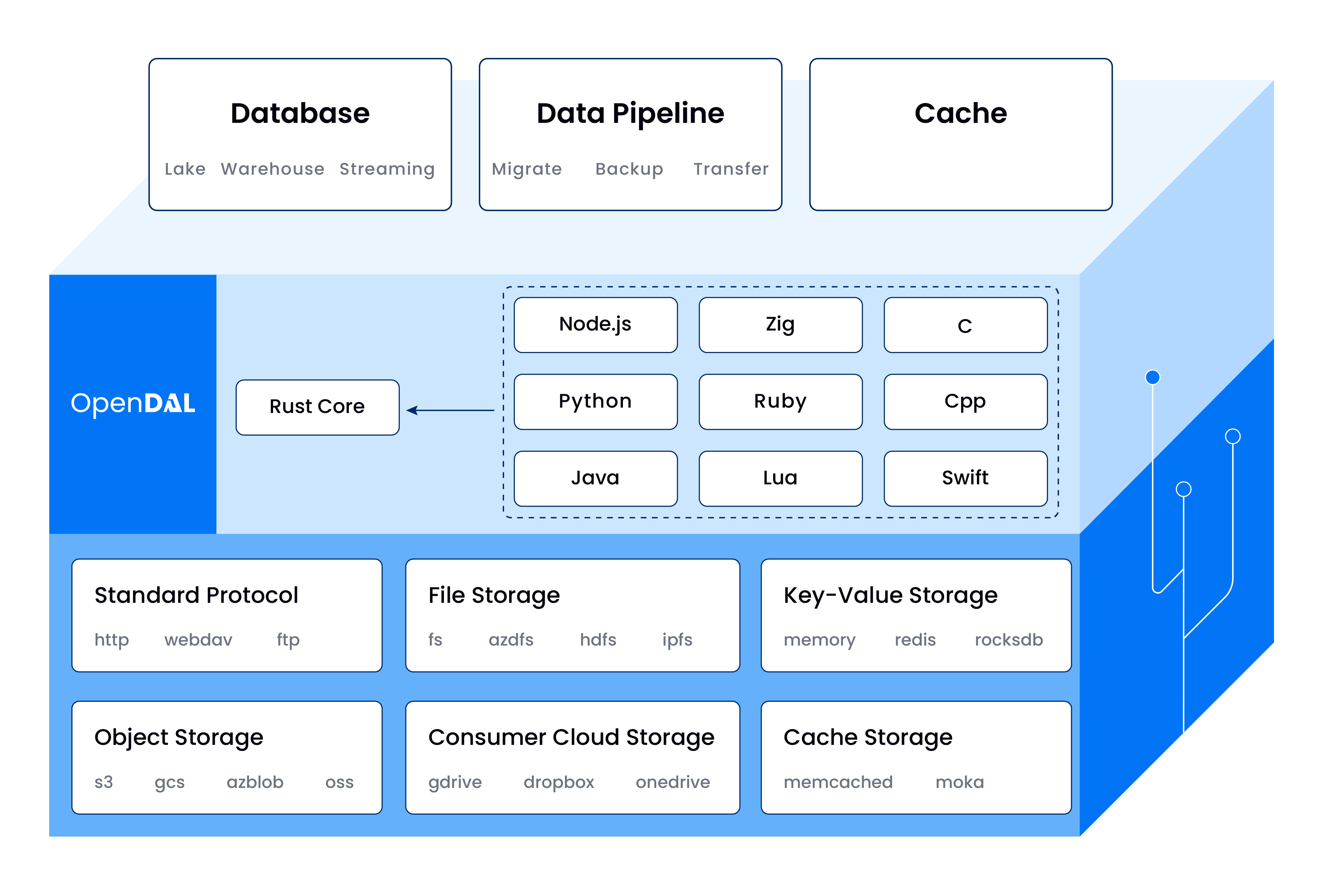
Apache OpenDAL™ is a data access layer that allows users to easily and efficiently retrieve data from various storage services in a unified way.
OpenDAL allows users to access data like the following:
#[tokio::main]
async fn main() -> Result<()> {
// Pick a builder and configure it.
let mut builder = services::S3::default();
builder.bucket("test");
// Init an operator
let op = Operator::new(builder)?.finish();
// Write data
op.write("hello.txt", "Hello, World!").await?;
// Read data
let bs = op.read("hello.txt").await?;
// Fetch metadata
let meta = op.stat("hello.txt").await?;
let length = meta.content_length();
// Delete
op.delete("hello.txt").await?;
Ok(())
}As illustrated in the code example, OpenDAL offers a unified interface for accessing data from various types of storage services via a designated path. The data focus here is primarily on non-structured data—often referred to as files, binaries, or blobs. This means that OpenDAL is agnostic about the content of the data and it is adept at performing read and write operations on it.
Abstraction limitation
Like any software component, OpenDAL has its specific scope and limitations. OpenDAL is engineered to serve as a data access layer that operates through file-based paths. This design choice means it isn't suited for handling database access for several reasons:
- In database systems, data retrieval is typically based on table and column identifiers, not file paths. Consequently, this would require SQL query construction, which falls outside OpenDAL's design.
- Accessing Binary Large Objects (BLOBs) in databases could result in performance bottlenecks, given that databases are generally not optimized for this use-case.
- Furthermore, databases are not well-suited for storing large BLOBs, making them an impractical choice for data types that OpenDAL may commonly handle.
Given these factors, OpenDAL is not designed to work with relational databases like PostgreSQL and MySQL.
A Real Use Case
But, but, but, we never know how users use OpenDAL, right?
One of OpenDAL's users presented a use case involving the need to persist numerous small files, each under 4KiB, with an average size of 1KiB. For them, the optimal solution is to store these files in an existing database like PostgreSQL or MySQL. They prefer this approach to avoid introducing additional infrastructure components.
After some investigation, the users found that OpenDAL is an ideal fit for their needs:
- OpenDAL offers a unified interface for accessing various storage services, which is crucial given their corporation's diverse infrastructure setups.
- OpenDAL's abstraction allows for operations like reading, writing, listing, and deleting data via a specified path (or key).
They were attracted to OpenDAL's existing support for Redis and RocksDB and approached me to discuss the potential for adding PostgreSQL and MySQL support. I took some time to ponder this use case. While our earlier conclusion still holds—OpenDAL is not originally intended for use with relational databases—the reality is that databases do offer BLOB support, and there is a user demand for accessing BLOBs within them. Essentially, users would end up building functionality similar to OpenDAL's but tailored for database BLOBs. So, why not incorporate this capability directly into OpenDAL?
Start with PostgreSQL
After realizing the new use case, I began considering how to implement it in a manner consistent with OpenDAL's design philosophy.
Several fundamental ideas are clear:
- I have a preference for PostgreSQL, so that will be my starting point.
- OpenDAL will continue to use the
pathconcept for data access, constructing the appropriate SQL queries for PostgreSQL. - The
BYTEAdata type can be utilized to store data within PostgreSQL.
I've initiated a pull request titled: feat: Add PostgreSQL Support to OpenDAL. After this PR, @Zheaoli also added support for MySQL and SQLite.
Users can interact with PostgreSQL through OpenDAL as follows:
#[tokio::main]
async fn main() -> Result<()> {
let mut builder = Postgresql::default();
builder.root("/");
builder.connection_string("postgresql://your_username:your_password@127.0.0.1:5432/your_database");
builder.table("your_table");
// key field type in the table should be compatible with Rust's &str like text
builder.key_field("key");
// value field type in the table should be compatible with Rust's Vec<u8> like bytea
builder.value_field("value");
// Init an operator
let op = Operator::new(builder)?.finish();
// Write data
op.write("hello.txt", "Hello, World!").await?;
// Read data
let bs = op.read("hello.txt").await?;
// Fetch metadata
let meta = op.stat("hello.txt").await?;
let length = meta.content_length();
// Delete
op.delete("hello.txt").await?;
Ok(())
}Future
This feature is cool because it addresses real-world use cases that align with OpenDAL's vision.
There are still many things to do, like:
- Add SurrealDB, MongoDB and so on.
- Polish the kv adapter API so we can support query pushdown instead of just iter the whole prefix.
I'm looking forward to seeing how OpenDAL evolves in the future. If you have any ideas, please feel free to open an issue.
Thanks for reading!