Hello everyone, welcome to my November 2025 edition about How I Coding. We just went through a wild month with many new SOTA models released:
- gpt-5.1
- gpt-5.1-codex
- gpt-5.1-codex-max
- gemini-3-pro
- claude-opus-4.5
Sadly, I didn't have a chance to evaluate them all. It doesn't make sense to just test one or two tasks on new models and throw out random ideas to my readers. This month's edition will focus only on the GPT services of models and my experiments with them, as well as the new changes to my toolset.
I didn't keep up with the latest models, but I think it's more honest and more valuable for your time.
Mindset
Prompts Raising Again
I used to believe that prompts didn't matter. It was more important to give the models correct and valuable context. I always thought that if you needed to tune prompts to get the model to behave correctly, it was time to upgrade to a new model.
However, my recent experience with gpt-5.1-codex-max has changed this idea a lot. I now think prompts are rising again in importance for agentic coding.
There are two reasons for this shift.
First, model capability keeps growing. New models align better with user input. For models that strongly prioritize following instructions, incorrect prompts make it much easier for the model to behave incorrectly.
This is especially obvious with gpt-5.1-codex-max, and even more so with higher reasoning tasks. I used to write instructions like "think from first principles, check in with the user when you hit blocks." But codex-max with xhigh will ask for clarification at every step.
I fixed this by polishing the AGENTS.md file to better guide codex-max's behavior.
This makes me think that different models may increasingly develop distinct characteristics. As users, we'll need to identify and refine our prompts to match each model's style.
Second, in agentic coding, the model usually finds its own context. The first prompt is the most important thing for the agent to perform tasks correctly. So in agentic contexts, context mainly comes from the user's prompt itself. Better prompts lead to better outputs.
In conclusion, it's worth stepping back and polishing the AGETNS.md for a while. Also there's a tradeoff here. We're software engineers with real problems to solve, and it's unacceptable to spend too much time on prompts instead of our actual work.
Optimize AGENTS.md
I suggest everyone optimize the AGENTS.md in a feedback loop. I optimized it this way:
First, follow the prompt guidelines from OpenAI and Anthropic to get a general sense of how models behave.
Then ask gpt-5.1-pro for detailed suggestions.
Pick a task that represents your daily work. This task shouldn't be too easy, something can fix in one loop, nor too complex that hard to evaluate quickly. The best tasks take 3 to 5 rounds of discussion and can be evaluated in seconds.
Observe the agent's behavior, not just speed or accuracy. Pay attention to how the model acts when it hits a block. Notice how it responds when you point out its mistakes.
Record your findings and repeat the loop until the model behaves the way you want.
Optimize whenever you switch to a new model or tool. It's also useful to check in every month.
But one thing to remember: don't spend too much time on this. LLMs are generating, not thinking. You can't fully control exactly how they behave. If you spend hours and the model still doesn't work as you'd like, try a different one.
Toolset
I'm using gpt-5.1-codex-max with high for now because I found xhigh on codex-max always overthinks and follows instructions too strictly.
Starting from the end of this month, I switched from xlaude to Conductor.Conductor can create parallel Codex and Claude code agents in isolated workspaces. It essentially does the same thing as xlaude but with a much better UI and UX.
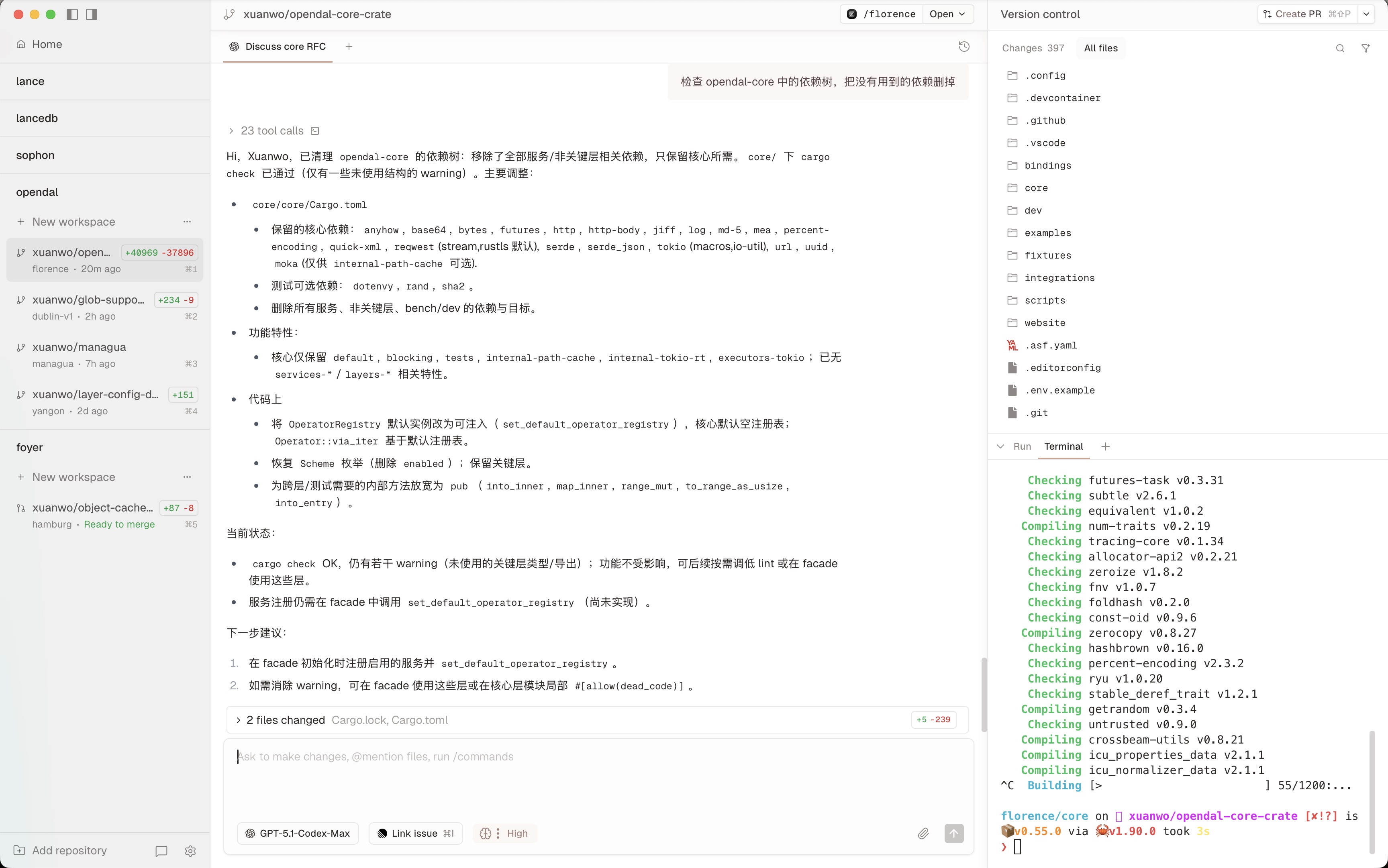
In Conductor, you can create new workspaces for a given project with one click. Each workspace is a worktree: an entirely isolated copy of your codebase. Within a workspace, you can create multiple tabs to run agents on the same codebase, which is great for research and review.
One nice feature Conductor provides is the ability to share context between tabs.
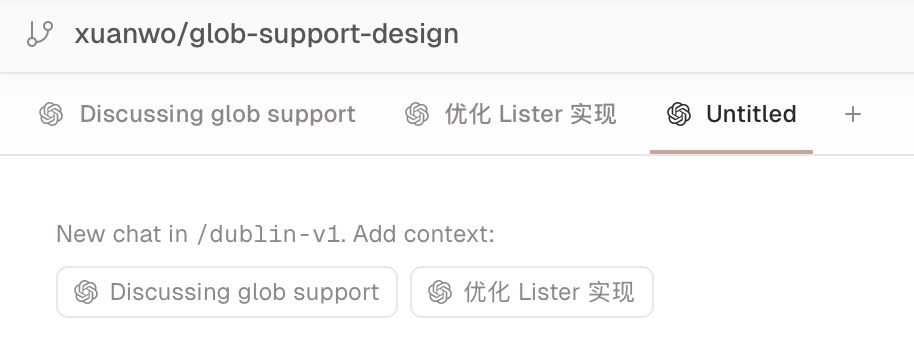
As shown in the picture, if you start a new tab in an existing workspace, you can just add context inside the new tab so you can continue the discussion or spawn other tasks.

Conductor has built-in code review features where you can ask about code changes without copying the code.
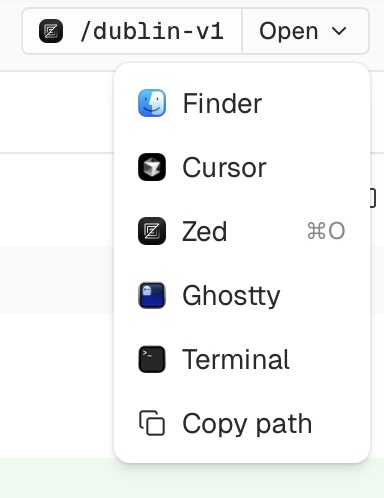
Conductor also lets you open the editor or terminal directly from a given workspace. That's my favorite feature. I used to open Zed to review changes while work is being done.
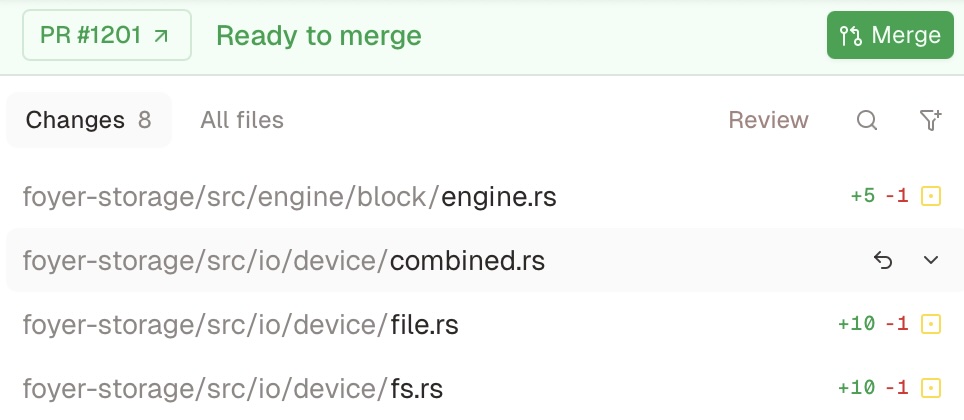
Conductor also provides nice integration with GitHub and Linear.
I won't share all nice features one by one here. It's free to use for now, just go to https://conductor.build to give it a try.
Tips
Benchmarks can't reflect a model's real experience.
The most important tip I want to share is that benchmarks can't reflect a model's real experience. A model could be super smart and solve the hardest math problem but still fail to follow instructions correctly, or just write code full of Any.
I suggest everyone build their own evaluation system, a small one that reflects their daily work to understand how well the model fits their actual needs.
That's all, Hope you're enjoying the coding as before!